
- CXL extiende PCIe con coherencia de memoria y memory pooling, permitiendo arquitecturas heterogéneas mucho más flexibles.
- NVLink y UALink se especializan en comunicación intensiva entre aceleradores, mientras CXL orquesta el modelo de memoria compartida.
- Las infraestructuras de IA modernas combinan varios fabrics en capas: NVLink/UALink intra‑nodo, CXL para memoria y red Ethernet/InfiniBand entre racks.
- El futuro apunta a centros de datos desagregados, con cómputo y memoria como recursos compartidos conectados mediante CXL y fabrics ópticos de alta velocidad.
La revolución de la inteligencia artificial a gran escala no va solo de modelos con miles de millones de parámetros; va, sobre todo, de cómo se mueven y comparten los datos entre CPU, GPU y aceleradores especializados. Cuando hablamos de entrenar LLM enormes o de servir inferencias con contextos kilométricos, el cuello de botella real suele estar en la interconexión y la memoria, no en la potencia bruta de cómputo.
En este escenario, la arquitectura heterogénea basada en CXL (Compute Express Link) se ha convertido en una de las grandes apuestas de la industria: un estándar abierto que se apoya en PCI Express pero añade coherencia de memoria y mecanismos de pooling que cambian por completo cómo se diseñan servidores, racks y centros de datos. A su alrededor orbitan otras piezas clave como NVLink, UALink o propuestas más agresivas tipo UB‑Mesh, que se combinan para construir los sistemas de IA de nueva generación.
Por qué la interconexión es crítica en la era de la IA
Cuando desplegamos modelos de IA gigantes, el reto ya no es solo «tener más GPUs», sino lograr que todos los aceleradores trabajen como si fueran un único cerebro, compartiendo parámetros, gradientes y activaciones sin ahogarse en latencia ni desperdiciar ancho de banda.
Durante el entrenamiento distribuido, se produce un flujo masivo de datos entre dispositivos: hay que sincronizar gradientes, repartir lotes, hacer operaciones colectivas como all‑reduce o all‑gather y mantener consistencia entre replicas del modelo. Si este intercambio se hace mediante interconexiones lentas o poco eficientes, el rendimiento global se desploma por muy potentes que sean las GPUs.
Además, los sistemas actuales tienden a compartir cada vez más la memoria entre CPU, GPU y otros aceleradores. Esto implica dotar al hardware de mecanismos de coherencia de memoria sofisticados, de forma que todos vean los mismos datos actualizados sin copias redundantes ni inconsistencias. Y aquí es donde tecnologías como CXL dan un salto cualitativo frente al PCIe «clásico».
Otro aspecto clave es cómo escalamos: algunas arquitecturas apuestan por el scale‑up (muchos aceleradores en un solo nodo o rack), mientras que otras tiran más hacia el scale‑out (muchos nodos conectados en red). En la práctica, los grandes clústeres de IA combinan ambos enfoques, así que el tejido de interconexión tiene que rendir bien tanto dentro del nodo como entre nodos.
Y todo esto hay que hacerlo cuidando la latencia y la eficiencia energética. A frecuencias altísimas, el coste de las colas, los buffers, la lógica de protocolo y las retransmisiones puede comerse una parte importante del supuesto beneficio del mayor ancho de banda físico. Además, mover bits es caro en términos de vatios, por lo que la arquitectura completa (enlaces, switches, cableado, óptica) debe diseñarse pensando también en consumo y refrigeración.
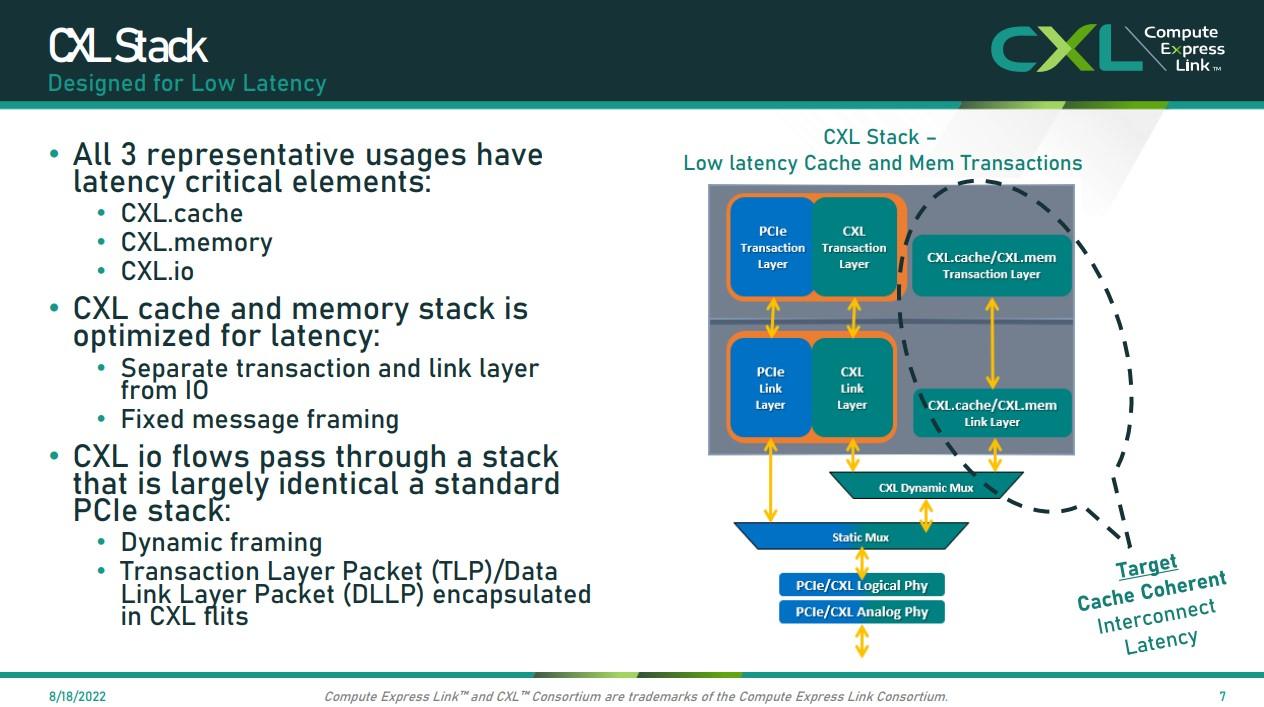
De PCI Express a fabrics especializados
Aunque a veces se nos olvida, casi todo este ecosistema se apoya sobre PCI Express como base física y eléctrica. PCIe define cómo se codifican las señales, cómo se organizan las lanes, cómo se negocian velocidades y cómo se configuran los dispositivos. Sus sucesivas generaciones (Gen1 a Gen7) han ido duplicando el ancho de banda efectivo casi en cada salto.
Ahora bien, PCIe por sí solo está pensado para un modelo relativamente sencillo: host-dispositivo, sin coherencia de memoria avanzada entre múltiples agentes y sin operaciones colectivas optimizadas para cargas tipo IA. Para entrenar modelos masivos, PCIe puro se queda corto tanto en latencia como en ergonomía de programación.
A partir de esa limitación aparecen interconexiones especializadas como NVLink (NVIDIA), Compute Express Link (CXL) o UALink, además de viejas conocidas como InfiniBand y Ethernet para el tramo de red. En la práctica, los sistemas de máximo rendimiento combinan varias de estas tecnologías en capas: PCIe como cimiento, CXL como tejido coherente de memoria, y enlaces tipo NVLink o UALink para tráfico intensivo entre aceleradores.
NVLink: la apuesta propietaria de NVIDIA
NVLink es la tecnología de interconexión de altas prestaciones de NVIDIA pensada, sobre todo, para comunicación directa entre GPUs y, en algunos casos, entre CPU y GPU dentro de arquitecturas heterogéneas como Grace Hopper.
En términos de diseño, NVLink agrupa varias líneas de alta velocidad en enlaces punto a punto que se pueden cablear en diferentes topologías. Una de las más habituales en sistemas de IA es la topología de malla o variantes de malla plena, que permiten que cada GPU se comunique con varias vecinas directamente, reduciendo saltos intermedios y latencia.
La pieza clave para escalar dentro de un nodo es NVSwitch, un conmutador específicamente diseñado para manejar decenas de enlaces NVLink y crear dominios de comunicación muy densos (pensemos en máquinas con 8, 16, 32 o más GPUs que comparten un único espacio de memoria virtual). Sobre esa base se soportan operaciones colectivas de altísimo rendimiento a través de librerías como NCCL.
En el ámbito CPU-GPU, NVIDIA ha introducido NVLink‑C2C (Chip‑to‑Chip), un enlace de muy baja latencia que puede proporcionar on the order de cientos de GB/s bidireccionales entre un procesador CPU Grace y una GPU Hopper, con coherencia de memoria entre ambos. De esta forma, los datos pueden residir donde más convenga sin penalizaciones brutales por cruces de bus.
Las ventajas de NVLink son claras: ofrece un ancho de banda por enlace muy superior al de PCIe, está extremadamente afinado para operaciones colectivas típicas del entrenamiento distribuido, y su integración con el ecosistema CUDA hace que el programador no tenga que reinventar la rueda para sacarle partido. En cargas de IA dentro del ecosistema NVIDIA, es un auténtico game changer.
Pero tiene también sus pegas: es una tecnología cerrada y muy asociada al hardware de NVIDIA, por lo que no se usa fuera de ese ecosistema. A gran escala, cuando queremos conectar muchos nodos en un clúster, hay que recurrir igualmente a InfiniBand o Ethernet, ya que NVLink está pensado sobre todo para la conectividad intra‑nodo o intra‑rack. Además, la complejidad y el coste de desplegar grandes dominios NVLink (NVSwitch, backplanes, cableado) no son precisamente bajos.
Para suavizar esta rigidez, NVIDIA ha empezado a hablar de NVLink Fusion, una iniciativa pensada para que otros tipos de procesadores o aceleradores puedan integrarse en dominios NVLink sin necesidad de ser GPUs puras. La idea es ir hacia un entorno algo más heterogéneo manteniendo el control del fabric.

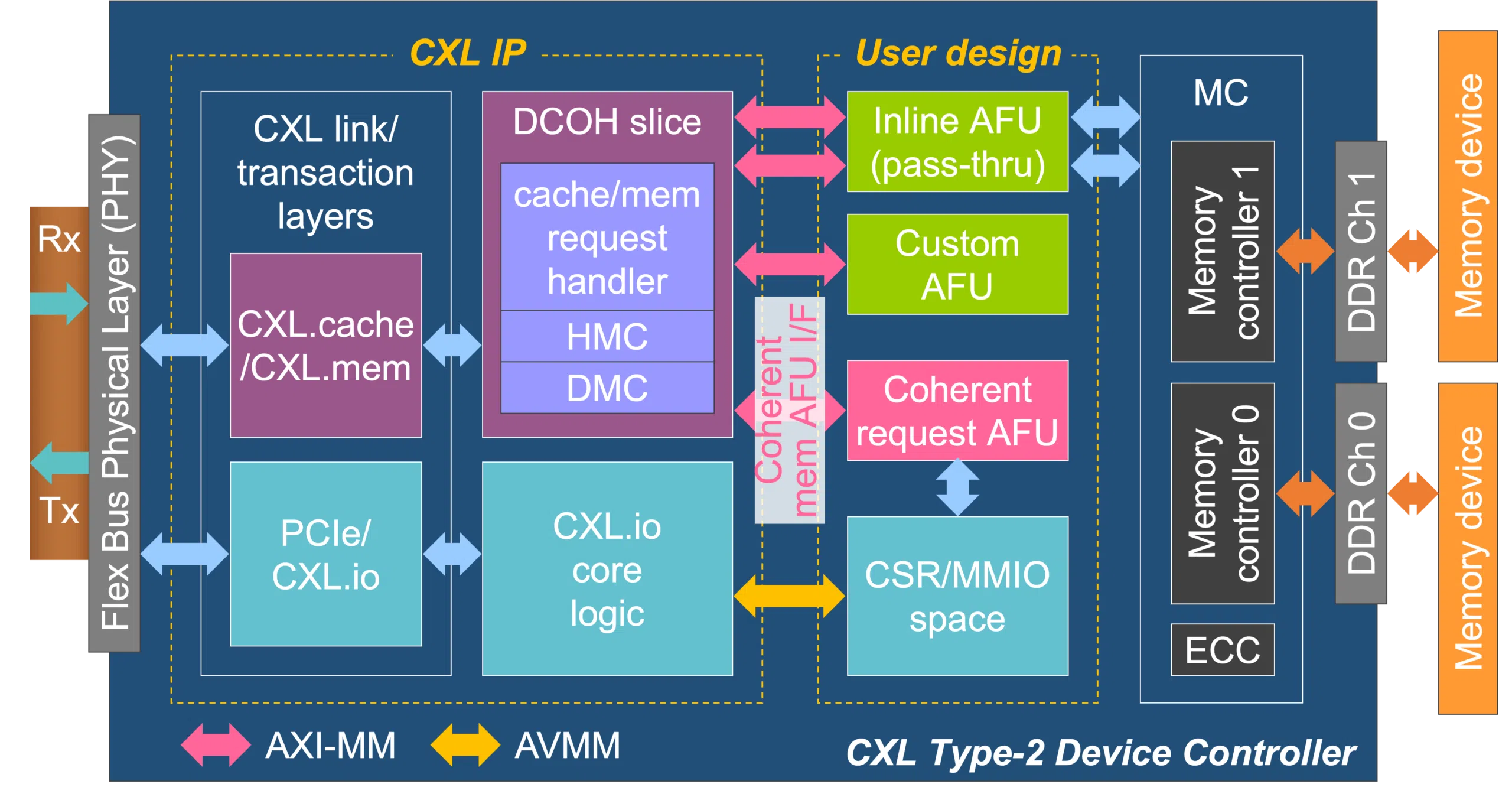
CXL (Compute Express Link): el estándar abierto para memoria coherente
CXL es un estándar abierto promovido por un consorcio amplio de la industria que incluye a fabricantes de CPUs, GPUs, FPGAs, memorias y grandes proveedores de la nube. Su objetivo es bastante ambicioso: proporcionar una interconexión coherente y flexible entre procesadores y dispositivos, apoyándose en la capa física de PCIe pero añadiendo un protocolo mucho más rico.
A nivel técnico, CXL multiplexa tres subprotocolos en un mismo enlace. El primero, CXL.io, mantiene compatibilidad con el comportamiento típico de PCIe (configuración, espacio de direcciones, interrupciones, DMA). Es, en esencia, el pegamento que permite que un dispositivo CXL siga apareciendo como un dispositivo PCIe estándar a ojos del sistema operativo.
Los dos subprotocolos verdaderamente diferenciales son CXL.cache y CXL.memory. CXL.cache permite que un dispositivo (por ejemplo, una GPU o un acelerador específico) mantenga una caché coherente de la memoria del host, integrándose en el protocolo de coherencia de la CPU. CXL.memory, por su parte, hace posible que la CPU acceda a la memoria local de un dispositivo como si fuera una extensión de la DRAM del sistema, con coherencia y sin tener que recurrir a trucos de direccionamiento exótico.
Las sucesivas versiones del estándar han ido ampliando sus capacidades. CXL 2.0 añadió, entre otras cosas, el soporte para switches y dispositivos de memoria tipo pool, permitiendo que varios hosts compartan bancos de memoria CXL y que se puedan ampliar las capacidades de forma modular. CXL 3.0 da un paso más al habilitar topologías multi‑nivel, tráfico peer‑to‑peer entre dispositivos sin pasar necesariamente por la CPU y mejoras para arquitecturas desagregadas en las que CPU, memoria y aceleradores no tienen por qué vivir en el mismo chasis.
En este contexto, suele hablarse de distintos tipos de dispositivos CXL. Los de tipo 1 son aceleradores sin memoria propia significativa (por ejemplo, ciertas tarjetas de red inteligentes) que se benefician de acceder a la RAM del host con coherencia. Los de tipo 2 son dispositivos con memoria local (GPUs, FPGAs, ASICs) que pueden exponerla y compartir coherencia con la CPU. Los de tipo 3 son módulos de memoria puros (expansores de RAM, memoria de alta capacidad o mayor latencia) que amplían el espacio de memoria del sistema o sirven de pool compartido.
La gran baza de CXL es que permite romper el acoplamiento rígido entre CPU y memoria. Gracias a los switches CXL y a los dispositivos tipo 3, es posible crear pools masivos de memoria compartida donde varios hosts «alquilan» trozos de capacidad en función de sus necesidades. Trabajos académicos como Octopus exploran precisamente cómo construir estos pools de forma escalable y barata, mientras que otros, como CXL‑NDP, estudian cómo acercar computación a estos bancos para, por ejemplo, comprimir o descomprimir datos in‑situ.
Tampoco todo son ventajas. Al construirse sobre la misma base física que PCIe, CXL no puede competir en latencia absoluta con enlaces diseñados ad hoc como NVLink para comunicación GPU-GPU dentro del mismo servidor. Además, el diseño de switches CXL que mantengan coherencia distribuida, arbitren bien el tráfico y eviten estados inconsistentes es bastante complejo. Y, a día de hoy, muchos aceleradores de gama altísima siguen apostando por interconexiones propietarias para exprimir hasta el último punto porcentual de rendimiento.
Relación entre CXL y PCI Express en hardware real
Una duda frecuente es hasta qué punto CXL depende de PCI Express y qué implica esto a nivel de hardware de consumo. Las primeras versiones del estándar, CXL 1.0 y 2.0, se definieron sobre la capa física de PCIe 5.0, mientras que CXL 3.0 ya se apoya en PCIe 6.0. No existen implementaciones oficiales de CXL sobre generaciones más antiguas de PCIe, así que si una plataforma no soporta al menos PCIe 5.0 en el controlador raíz, no podrá ofrecer CXL «de verdad».
Además, para que las funciones avanzadas de CXL entren en juego, no basta con que el chipset o la placa base entiendan el estándar: los propios dispositivos deben estar diseñados para implementar CXL.io, CXL.cache y CXL.memory. Por eso, hoy por hoy, vemos CXL principalmente en placas para servidores, estaciones de trabajo muy específicas y plataformas de centro de datos, mientras que en el PC de escritorio convencional el soporte real es prácticamente inexistente.
En la práctica, CXL habilita cosas tan interesantes como usar módulos de memoria «externos» a la CPU como si fueran parte del espacio de direcciones principal, o permitir que una GPU pueda ir más allá de su VRAM soldada accediendo a memoria CXL de tipo 3 cuando se queda corta. En cargas como el entrenamiento de modelos de IA donde la memoria es el principal límite, esta capacidad de «estirar» la memoria disponible sin rediseñar todo el sistema puede marcar la diferencia.
Al mismo tiempo, el uso de CXL en combinación con sockets convencionales de memoria permite plantear arquitecturas cliente algo más flexibles. Por ejemplo, en teoría, un fabricante podría ofrecer APUs con un ancho de banda efectivo de cientos de GB/s hacia memoria a través de CXL y canales DDR5 estándar, reduciendo la necesidad de sockets HEDT específicos en muchos casos de uso intermedios.
Memory pooling y desagregación con CXL 2.0 y 3.0
A partir de CXL 2.0, entra en juego de lleno el concepto de memory pooling. En lugar de que cada CPU tenga su propio conjunto de DIMMs fijados de por vida, podemos imaginar un chasis con uno o varios switches CXL a los que se conectan módulos de memoria tipo 3 y varios hosts. Cada servidor «ve» solo una parte del pool, pero esa parte se puede reconfigurar dinámicamente según la carga.
Para evitar conflictos en el acceso, el estándar contempla mecanismos de asignación de regiones de memoria a dispositivos concretos y usa CXL.cache como especie de gran caché de último nivel que amortigua la latencia de acceder a memorias que están físicamente más lejos que la DRAM local. Así se intenta que un acelerador no tenga que peinar bancos gigantes de memoria remota para encontrar los datos que necesita.
Un ejemplo muy ilustrativo: imaginemos una GPU entrenando un modelo cuyo estado completo no cabe ni de lejos en su VRAM integrada. Mediante CXL, esta GPU podría rebasar el límite físico de su propia memoria local, utilizando parte de la RAM del host, parte de la memoria de otra GPU CXL‑compatible o incluso un módulo de memoria dedicado en un slot CXL tipo 3. Desde el punto de vista del software, se podría mapear todo ese espacio en un único rango de direcciones.
Esto es especialmente potente en sistemas donde la memoria soldada no se puede ampliar (tarjetas gráficas, muchos SoCs, aceleradores específicos). La posibilidad de complementarla con extensores de memoria CXL multiplica la flexibilidad del diseño, aunque haya que gestionar con cuidado las diferencias de latencia y ancho de banda entre los distintos niveles de la jerarquía.
UALink y otras alternativas emergentes
Mientras CXL se centra en la coherencia y el modelo de memoria, otras iniciativas recientes atacan específicamente el problema de la comunicación intensiva entre aceleradores. Una de las que más ruido ha hecho es UALink (Ultra Accelerator Link), un estándar orientado a conectar grandes cantidades de GPUs y otros aceleradores dentro de lo que se suele llamar un «AI pod».
UALink 1.0 se basa en una capa física derivada de Ultra Ethernet (P802.3dj) y define enlaces de unos 200 Gbps por dirección para crear dominios con hasta 1024 aceleradores interconectados mediante switches UALink (ULS). Cada puerto recibe un identificador único dentro del pod, lo que permite topologías bastante flexibles y conmutación a gran escala.
En el plano de coherencia, UALink puede aprovechar tecnologías como Infinity Fabric de AMD para gestionar la visibilidad de memoria entre aceleradores del mismo dominio. La idea general es ofrecer una alternativa más abierta a las soluciones propietarias de un único fabricante, sin renunciar a un nivel de rendimiento muy alto.
En paralelo, hay otros estándares de interconexión como Gen‑Z, CCIX, OpenCAPI o CAPI que en su día aspiraron a resolver el problema de la memoria coherente y la desagregación de recursos. Algunos se han ido diluyendo a medida que CXL ganaba tracción y que NVLink consolidaba su posición en el segmento de la IA de máximo rendimiento, pero muchos de sus conceptos han influido en el diseño de CXL y de las arquitecturas actuales.
Diseños híbridos: combinar CXL, NVLink, UALink y red
La realidad de los grandes centros de datos es que no existe un único estándar que cubra bien todas las necesidades. Por eso empiezan a proliferar diseños híbridos en varias capas. Por ejemplo, es bastante razonable usar NVLink o UALink para la comunicación intensiva entre GPUs dentro de un nodo, CXL para compartir memoria entre CPU y aceleradores, y Ethernet o InfiniBand como red de interconexión entre racks.
En el mundo académico han surgido propuestas que formalizan este enfoque híbrido. Panmnesia, por ejemplo, plantea una arquitectura que combina CXL con enlaces tipo UALink/NVLink para compartir memoria entre nodos y, al mismo tiempo, ofrecer una red dedicada de alta velocidad para las comunicaciones directo entre aceleradores. La idea es reducir los cuellos de botella que se formarían si todo el tráfico tuviera que pasar por la CPU.
Otra propuesta, DFabric, sugiere un tejido de dos niveles: un fabric CXL intra‑rack que proporciona acceso eficiente a memoria compartida y recursos de red, y sobre él un sistema de pooling de NICs (interfaces de red) que se pueden reasignar y compartir entre nodos. Esto permite que varios servidores se aprovechen de menos tarjetas de red físicas, pero de mayor capacidad, reduciendo costes y mejorando la utilización.
En paralelo, algunos fabricantes están explorando arquitecturas aún más integradoras, como UB‑Mesh de Huawei, que pretende unificar en un único protocolo en malla diferentes formas de tráfico: PCIe, CXL, NVLink, TCP/IP, etc. La visión es que todo el centro de datos se comporte como una especie de «SuperNodo» donde la distinción entre tráfico interno al servidor y tráfico de red externa se difumina. Es una apuesta ambiciosa y todavía joven, pero apunta hacia la posible convergencia futura de muchas de estas capas.
Escenarios de uso en arquitecturas de IA modernas
Para aterrizar todo esto, conviene ver cómo se utilizan en la práctica NVLink, CXL, UALink y compañía en diferentes tipos de cargas de trabajo relacionadas con IA.
En el entrenamiento distribuido intensivo dentro de un solo nodo o chasis (scale‑up), lo normal es que un dominio NVLink bien diseñado conecte, por ejemplo, 8 o 16 GPUs mediante NVSwitch. En estos casos, todas las GPUs pueden compartir parte del espacio de memoria como si fuera una única gran VRAM, lo que simplifica mucho el particionado de modelos y los algoritmos de entrenamiento paralelo. CXL puede entrar en juego aquí como capa de expansión de memoria para alojar parámetros muy grandes o estados que no caben cómodamente en la memoria de las GPUs.
En inferencia de modelos grandes, con contextos muy extensos (por ejemplo, LLMs que manejan cientos de miles de tokens de contexto), el gran problema es dónde guardar de forma eficiente las keys y values de la atención, que pueden crecer hasta tamaños enormes. NVLink resulta muy útil para que varias GPUs compartan esos datos en tiempo real sin tener que duplicarlos en cada dispositivo. Si el contexto o el propio modelo supera la suma de la memoria de las GPUs, CXL puede proporcionar un nivel de memoria adicional, más lento pero coherente, donde mantener partes menos activas del estado.
A escala de centro de datos (scale‑out), lo habitual es combinar varios racks, cada uno con su propia «isla» de NVLink o UALink, interconectados mediante Ethernet o InfiniBand. En este nivel, CXL puede utilizarse dentro de cada rack para crear pools de memoria compartidos entre nodos vecinos, mejorando la utilización de recursos y facilitando el despliegue de cargas con necesidades de memoria variables sin tener que mover constantemente máquinas virtuales o contenedores.
De cara al futuro, es muy probable que veamos arquitecturas heterogéneas donde convivan GPUs, TPUs, aceleradores de inferencia específicos, FPGAs para lógica personalizada e incluso procesadores neuromórficos. En estos entornos, CXL sirve de lenguaje común para la memoria coherente, mientras que enlaces como NVLink o UALink se encargan de la comunicación de altísimo rendimiento entre subconjuntos concretos de aceleradores. Iniciativas como NVLink Fusion van claramente en esa dirección.
