
- El GPU passthrough con VFIO permite asignar una GPU física a una VM con rendimiento casi nativo usando KVM/QEMU y OVMF.
- Es imprescindible habilitar correctamente IOMMU en BIOS y kernel, tener grupos IOMMU limpios y vincular la GPU a vfio-pci.
- El uso de hugepages, pinning de CPU, virtio para red y discos y ajustes específicos para NVIDIA/AMD mejora notablemente la fluidez.
- Con una iGPU o segunda GPU para el host, es posible usar Linux a diario y lanzar un Windows invitado para juegos y tareas pesadas sin reinicios.
Montar un entorno de GPU passthrough con VFIO parece magia negra la primera vez que lo intentas: BIOS, IOMMU, grupos raros, XML de libvirt, errores 43 de NVIDIA, cuelgues aleatorios… Pero cuando lo dejas fino, tener un Windows o cualquier otro sistema virtualizado con rendimiento casi nativo en tu GPU es una auténtica maravilla para jugar, editar vídeo o trabajar con IA sin renunciar a tu escritorio Linux.
En esta guía vamos a repasar de forma muy detallada todo el proceso de GPU passthrough con VFIO, integrando lo que se sabe en Arch, Proxmox, Pop!_OS, Debian y otros entornos modernos, además de trucos para hugepages, pinning de CPU, mitigación de stuttering y las típicas trampas con NVIDIA y AMD. La idea es que, cuando termines de leer, tengas claro no solo el “cómo”, sino también el “por qué” de cada ajuste.
Qué es exactamente GPU passthrough con VFIO y qué te permite hacer
Cuando hablamos de GPU passthrough con VFIO nos referimos a usar KVM/QEMU como hipervisor y asignar directamente una GPU física (y sus dispositivos asociados) a una máquina virtual, en lugar de usar una GPU virtual emulada. Esa asignación directa se hace usando VFIO (Virtual Function I/O), que permite a la VM hablar con la tarjeta casi como si estuviera conectada directamente a una placa base real.
Este enfoque permite que un sistema invitado, generalmente Windows, alcance un rendimiento gráfico muy cercano al bare metal, ideal para juegos, edición de vídeo, CAD, ML/IA y cualquier carga 3D pesada. A cambio, el host Linux se queda sin esa GPU mientras la VM está encendida, salvo que uses técnicas avanzadas de rebind dinámico de drivers.
La gracia del asunto es que puedes tener un host Linux de uso diario (desarrollo, navegación, multimedia, docker, etc.) y, con un par de clics o un script, lanzar un Windows virtualizado con acceso directo a la GPU para jugar o usar software exclusivo de Windows sin reiniciar ni cambiar cables.

Requisitos de hardware y firmware para que VFIO funcione
Antes de escribir una sola línea de configuración necesitas comprobar que tu equipo cumple una serie de requisitos mínimos de virtualización e IOMMU. Sin esto, no hay passthrough que valga.
Lo primero es la CPU. Debe soportar virtualización por hardware y IOMMU: Intel VT-x + VT-d en procesadores Intel y AMD-V + AMD-Vi (SVM + IOMMU) en AMD. Casi todos los procesadores de sobremesa de los últimos años lo incluyen, pero no está de más confirmar la compatibilidad en las especificaciones del fabricante.
El segundo pilar es la placa base / chipset. No basta con que la CPU soporte IOMMU: el chipset y la BIOS también deben implementarlo correctamente, y además exponer grupos IOMMU bien aislados para que puedas pasar dispositivos concretos sin arrastrar medio sistema detrás.
También es necesario que la GPU invitada soporte UEFI. Casi todas las tarjetas modernas lo hacen, pero con modelos viejos merece la pena extraer la ROM y comprobar con herramientas como rom-parser que el VBIOS tiene imagen EFI (tipo 3) válida. Sin UEFI, OVMF no arrancará vídeo correctamente y te quedarás en negro.
En la práctica, para un setup cómodo, viene bien tener o bien un iGPU en la CPU (caso de Ryzen 8000G, Intel con UHD/Xe, etc.) o una segunda GPU dedicada para el host, de manera que puedas reservar una tarjeta exclusivamente para la VM y la otra para Linux. Es viable hacer malabares con una GPU única, pero la configuración se vuelve mucho más delicada.
Activar IOMMU en BIOS y en el kernel de Linux
El primer paso práctico es conseguir que el IOMMU esté activo tanto en BIOS/UEFI como en el kernel. Sin esto, VFIO no puede aislar dispositivos PCI ni crear grupos.
En la BIOS, busca opciones tipo “Intel VT-d”, “AMD-Vi”, “IOMMU”, “SVM” o similares; normalmente están en menús de CPU o chipset avanzado. Deben quedar todas en Enabled. En placas AMD modernas también verás opciones como ACS Enable, AER CAP, ARI Support, que conviene habilitar si las tienes para mejorar la separación de IOMMU.
Una vez arrancado Linux, toca pasarle la orden al kernel. Dependiendo del gestor de arranque (GRUB, systemd-boot, Proxmox integrado, etc.), deberás editar un archivo u otro, pero la idea es siempre añadir un parámetro de kernel que active el IOMMU.
Con GRUB, lo habitual es editar /etc/default/grub y añadir a GRUB_CMDLINE_LINUX_DEFAULT:
En Intel: intel_iommu=on iommu=pt
En AMD: amd_iommu=on iommu=pt o simplemente iommu=pt si el kernel ya detecta AMD-Vi automáticamente. Algunos setups combinan además nomodeset, pcie_acs_override=downstream,multifunction o initcall_blacklist=sysfb_init para evitar que el framebuffer del host secuestre la GPU o para partir grupos conflictivos.
En entornos con systemd-boot (caso típico de algunas instalaciones de Proxmox o Pop!_OS con systemd-boot) la línea equivalente está en /etc/kernel/cmdline, donde se mezcla el root, el modo de arranque y los flags IOMMU.
Tras actualizar GRUB o regenerar la configuración de systemd-boot, reinicia y comprueba con dmesg | grep -i iommu, grep -i dmar /var/log/dmesg o similares que el kernel anuncia algo como “Intel-IOMMU: enabled” o “AMD-Vi: Interrupt remapping enabled”. Si ves un aviso de ACS override, es normal si has añadido ese parámetro, pero conviene entender que implica menos aislamiento real.
VFIO, grupos IOMMU y aislamiento de la GPU
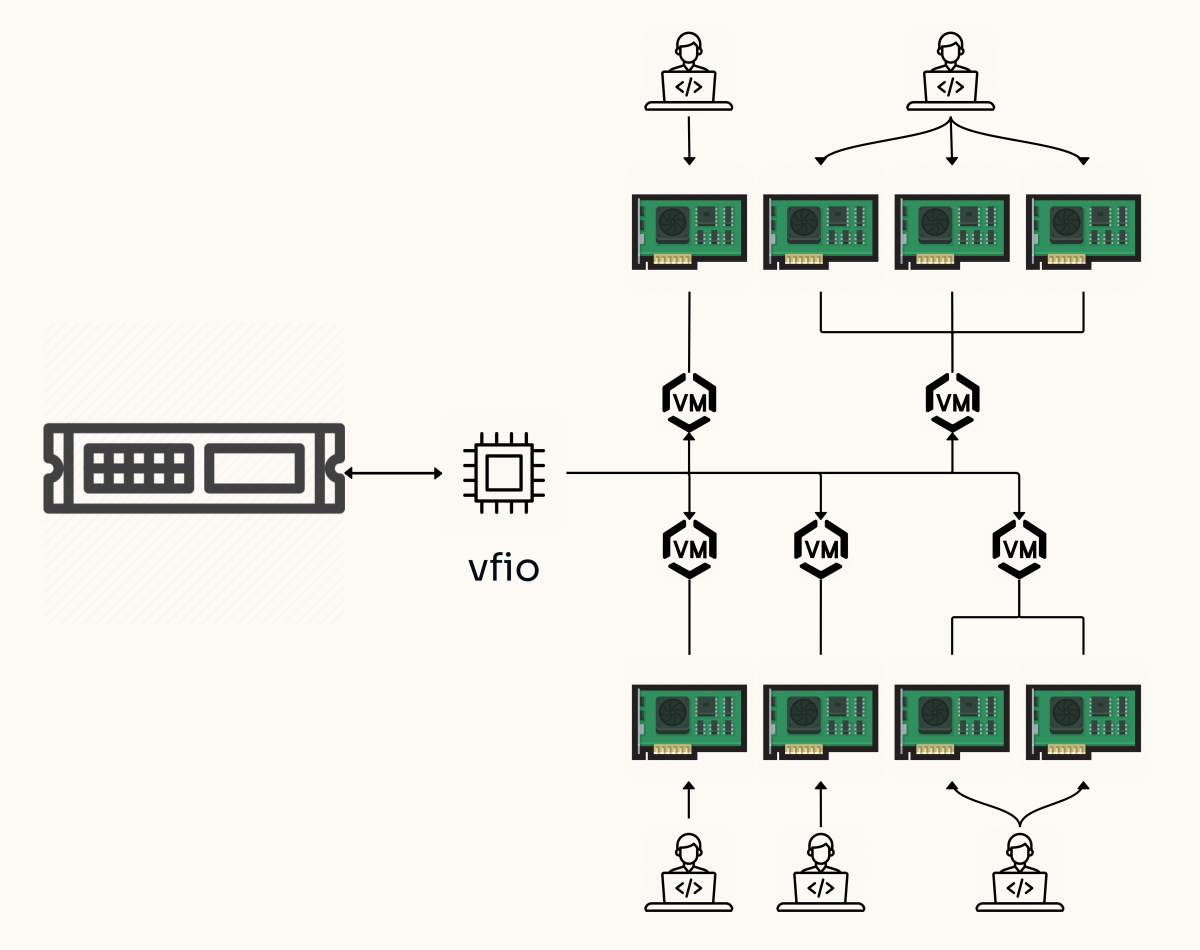
Con el IOMMU vivo, el siguiente paso es ver cómo agrupa el sistema los dispositivos PCI. El IOMMU no trabaja de forma individual por dispositivo, sino por grupos IOMMU, y todo lo que vaya en el mismo grupo debe pasarse junto a la VM o quedarse íntegro en el host.
La forma más cómoda de inspeccionar grupos es usar un pequeño script en bash que recorra /sys/kernel/iommu_groups y liste los dispositivos con lspci -nns. Así verás cosas como tu GPU, su controlador de audio HDMI, puentes PCIe, controladoras USB, etc. agrupados con un número de grupo.
Lo ideal es que la GPU destinada a la VM y su audio asociado aparezcan en un grupo aislado sin otros dispositivos críticos. Algo tipo: “IOMMU Group 13: 06:00.0 VGA… 06:00.1 Audio…”. Si en el grupo aparece también un puente PCI que solo cuelga de esa tarjeta, no suele ser un problema, pero si entran más cosas importantes, la cosa se complica.
Si los grupos no están limpios, tienes un par de vías. Una es probar otros slots PCIe físicos para la GPU, a veces cambia la topología y los grupos. La otra, bastante más agresiva, es usar el ACS override patch (a menudo vía kernel parcheado tipo linux-zen o kernel vfio), activado con pcie_acs_override=downstream,multifunction. Esto simula capacidades ACS donde no las hay, “rompiendo” grupos a costa de un potencial retroceso en seguridad.
Una vez tengas claro qué GPU y dispositivos relacionados vas a pasar, necesitas hacer que el host deje de usar sus drivers nativos (amdgpu, nvidia, nouveau, snd_hda_intel, etc.) y que desde el arranque tomen el control los módulos vfio.
Vincular la GPU a vfio-pci y gestionar los drivers del host
El módulo clave aquí es vfio-pci. Es el “driver” genérico que va a agarrar tu GPU en el host para quedársela reservada y exponerla a la VM sin que el sistema anfitrión la toque. Para ello hay dos estrategias principales: early binding por ID y rebind dinámico con scripts.
La opción más robusta para un entorno tipo servidor o Proxmox es hacer que vfio-pci tome la GPU desde el initramfs, antes de que Xorg, Wayland o los drivers de la gráfica se carguen. Esto suele implicar:
- Añadir vfio, vfio-pci, vfio_iommu_type1 y vfio_virqfd (según kernel) al listado de módulos a incluir en el initramfs.
- Inyectar en la línea de comandos del kernel un
vfio-pci.ids=VEN:DEV,VEN:DEVcon los IDs de tu GPU y su audio HDMI (por ejemplo10de:2b85,10de:22e8en un RTX de NVIDIA, o1002:67df,1002:aaf0en una RX 580). - Opcionalmente, blacklistear los drivers nativos con
modprobe.blacklist=nouveau,nvidia,nvidiafb,snd_hda_intelu otros equivalentes para AMD, de forma que sea imposible que se enganchen a la tarjeta.
Otra aproximación, más flexible cuando quieres usar la GPU en el host cuando la VM está apagada, es lo que hacen algunos tutoriales basados en libvirt hooks: al arrancar la VM se ejecuta un script que desvincula la GPU del driver nativo, la asocia a vfio-pci y lanza la máquina, y al apagar la VM otro script la devuelve al driver original. Es útil, por ejemplo, si quieres hacer CUDA o gaming en Linux y solo de vez en cuando pasar la GPU a un Windows invitado.
Sea cual sea tu enfoque, tras reiniciar deberías ver con lspci -nnk que el “Kernel driver in use” para la GPU y su Audio HDMI es vfio-pci y no amdgpu/nvidia/snd_hda_intel. Además, en dmesg | grep -i vfio deberían aparecer entradas indicando que se han añadido esos IDs al driver vfio-pci.
Si usas host gráfico con Wayland y una sola GPU, la cosa se complica bastante: host gráfico con Wayland tiende a agarrar la GPU muy pronto; muchos setups serios de passthrough siguen optando por Xorg clásico o bien una iGPU para el host y la dGPU para la VM para evitar este tipo de peleas.
OVMF, libvirt, virt-manager y creación de la máquina virtual
Con la parte baja del sistema en su sitio, toca construir la VM. La forma más cómoda en entornos de escritorio es usar libvirt + virt-manager + OVMF (firmware UEFI para QEMU). En servidores tipo Proxmox, el panel web hace algo similar por debajo.
En un host tipo Arch, Debian o Ubuntu necesitarás paquetes como qemu/KVM, libvirt, edk2-ovmf y virt-manager. Después se habilita y arranca el servicio de libvirtd, y se puede dejar configurada una red “default” con NAT para que las VMs salgan a Internet.
Al crear una VM nueva en virt-manager, selecciona instalación desde ISO (por ejemplo Windows 10/11) y decide si vas a usar un disco virtual (raw/qcow2) o bien vas a pasar un NVMe/SSD físico vía PCI. Esta segunda opción da un rendimiento I/O muy cercano al nativo, pero une más aún la VM al hardware.
Antes de iniciar la instalación, en el apartado “Overview” de la VM cambia el firmware a UEFI (OVMF_CODE.fd). Es vital para que la GPU con VBIOS UEFI arranque correctamente. También conviene cambiar el modelo de CPU a host-passthrough, para que el invitado vea todas las extensiones del procesador real (incluidas instrucciones AVX, AES, etc.) y evitar sorpresas con software exigente.
Para Windows, añade desde “Add Hardware” una unidad de CDROM con el ISO de drivers virtIO (netkvm, viostor, vioscsi…), que podrás instalar durante la instalación del sistema o justo después, de forma que la VM use dispositivos paravirtualizados y no controladoras IDE/SATA emuladas lentas.
Passthrough de la GPU, SSD y otros dispositivos PCI/USB
Con la VM definida, hay que adjuntar los dispositivos físicos que queremos pasar. Desde virt-manager, en “Add Hardware > PCI Host Device”, selecciona la GPU y todos los dispositivos del mismo grupo IOMMU que quieras pasar: normalmente la función VGA y el audio HDMI; si tu GPU trae USB integrado o similares, también habrá que añadirlos.
Si optas por pasar un SSD/NVMe completo por PCI, el invitado lo verá como un disco físico nativo y usará sus propios drivers (NVMe de Windows, por ejemplo), sin capa virtio-blk/virtio-scsi de por medio. Es la solución más limpia para un Windows gaming instalado directamente en una unidad dedicada.
Para controlar la VM, puedes:
- Pasar dispositivos USB enteros (teclado, ratón) mediante hostdev, sabiendo que mientras la VM esté encendida desaparecen del host.
- Usar Spice + QXL temporales durante la instalación y luego eliminarlos cuando tengas ya controlador de GPU en el invitado.
- En setups avanzados, emplear evdev o soluciones como Looking Glass (captura de framebuffer mediante IVSHMEM) para manejar la VM desde el escritorio del host sin cables extra.
En la configuración XML de libvirt se puede, además, clavar detalles finos: pinning de CPU, iothreads, configuración de Hyper-V enlightenments (para que Windows se crea que está sobre un hipervisor “legítimo”), clock, topología de sockets/cores/threads, etc.
Si tu GPU es NVIDIA GeForce, es posible que te encuentres con el famoso Error 43 en el administrador de dispositivos de Windows: NVIDIA detecta que está en una VM y desactiva la aceleración. Para “disfrazar” el hipervisor se suele:
- Añadir en
<hyperv>un vendor_id custom (cadena de hasta 12 caracteres). - Activar en
<kvm>el flag hidden state=’on’ para no exponer la hoja de CPUID de KVM. - En Q35/QEMU recientes, asegurarse de que el kernel_irqchip está en modo KVM completo o
<ioapic driver='kvm'/>para evitar comportamientos raros con interrupciones.
Hugepages, pinning de CPU y rendimiento casi nativo
Con la VM arrancando y la GPU funcionando, la siguiente fase es pulir el rendimiento: latencias, stutters, tiempos de carga y estabilidad, realizando pruebas de estrés como FurMark. Aquí entran en juego varios frentes: memoria, CPU, discos y energía.
La memoria se puede optimizar usando hugepages. En lugar de millones de páginas de 4 KiB, el host reserva bloques grandes (2 MiB o 1 GiB) que reducen la presión sobre la MMU y mejoran la TLB. QEMU puede usar transparent hugepages de serie (THP), pero si el host está fragmentado, acabarás con una mezcla de páginas grandes y pequeñas. Para setups sensibles a la latencia, suele ser preferible reservar hugepages estáticas o dinámicas antes de arrancar la VM.
Con hugepages estáticas, se añaden flags como default_hugepagesz=1G hugepagesz=1G hugepages=NUM al kernel, o se ajusta vm.nr_hugepages para páginas de 2 MiB. En la definición de la VM se mete un bloque <memoryBacking><hugepages/><locked/></memoryBacking> para indicarle que use esas páginas. Esto garantiza memoria contigua, pero la RAM asignada queda “secuestrada” incluso con la VM apagada.
Una alternativa más flexible es usar hugepages dinámicos, ya sea toqueteando /sys/kernel/mm/hugepages/.../nr_hugepages justo antes de arrancar la VM o mediante hooks de libvirt que hagan alloc_hugepages.sh al inicio y dealloc_hugepages.sh al final, liberando memoria al host al apagar la VM.
Otro bloque clave es el pinning de CPU. Sin pinning, los vCPUs de la VM son hilos que el scheduler del host mueve de core en core, vaciando la caché L1/L2/L3 y generando microcortes perceptibles en juegos. Con <cputune>, <vcpupin>, <emulatorpin> e <iothreadpin> puedes asignar vCPUs concretas a pares de hilos físicos (tomas de hyper-threading/SMT) que compartan núcleo y L3, manteniendo la VM fija sobre un conjunto de cores.
En la práctica, se suele dejar un bloque de cores para el host (por ejemplo core 0 y su hilo hermano) y asignar el resto a la VM, definiendo la topología con <cpu mode='host-passthrough'><topology sockets='1' cores='X' threads='2'/></cpu>. Si además se aíslan esos cores del host con isolcpus o con propiedades de systemd (AllowedCPUs en user.slice, system.slice, init.scope), la VM se libra de interferencias y el input lag baja notablemente.
Controladoras de disco virtio, redes rápidas y audio decente
En cuanto al almacenamiento, si no pasas un SSD físico, lo lógico es usar virtio-blk o virtio-scsi como backend de discos. Ambos son paravirtualizados, con soporte de TRIM y colas múltiples, y muy superiores a IDE/SATA emulados. Virtio-scsi añade algo de complejidad a cambio de más flexibilidad (un controlador SCSI puede colgar muchos discos), mientras que virtio-blk expone una controladora por cada disco.
Para sacarles partido, en el XML de la VM puedes definir iothreads y asociarlos a la controladora o al disco con iothread='1', eligiendo también el modo de I/O: io='native' (AIO del kernel, sin caché) o io='threads' (hilos de usuario para las operaciones de disco). Pinchando el iothread a cores del host no usados por la VM, evitas que la carga de I/O emulado provoque tirones en los vCPUs.
Para la red, el modelo virtio-net (o virtio-net-pci) es el estándar: rendimiento cercano al de una NIC real, especialmente si habilitas multiqueue (varias colas de transmisión/recepción) con <driver queues='8'/>. En el host puedes exponer esa interfaz sobre un bridge Linux clásico (br0) o con macvtap en modo bridge/vepa según tu topología.
El audio es otro clásico dolor de cabeza. Tienes varias opciones:
- Passthrough de la salida HDMI/DP de la GPU y conectar altavoces/monitor allí directamente, sin pasar por el host.
- Usar QEMU con backend PulseAudio o PipeWire, conectando el audio de la VM como si fuera otra app más del host, con posibilidad de ajustar latencia, mixingEngine, etc.
- Implementar soluciones específicas como Scream (envía audio por red/IVSHMEM) o JACK+PipeWire para setups profesionales de baja latencia.
En entornos con PipeWire moderno, se puede definir en el XML un <audio type="pipewire" ...> con rutas a /run/user/UID para que QEMU se conecte directamente al servidor de audio del usuario que lanza libvirt.
Casos especiales: AMD reset bug, NVIDIA móviles, RMRR, ACS y compañía
Más allá de la configuración básica, hay un montón de casuísticas especiales documentadas en wikis como la de Arch o foros de Proxmox que es bueno conocer.
Las GPUs AMD de ciertas generaciones (Polaris, Vega, alguna Navi) sufren el llamado reset bug: tras apagar la VM, la tarjeta no vuelve a un estado limpio y el siguiente arranque falla o cuelga el host. Una solución actualmente aceptada es cargar el módulo vendor-reset (vía paquete DKMS) y asegurarse, con systemd, de que se aplica el reset apropiado sobre el dispositivo PCI antes de que vfio-pci o el invitado intenten reutilizar la tarjeta.
En el mundo NVIDIA móvil (Optimus / Max-Q) hay el problema añadido de la detección de alimentación/batería por parte del driver. A veces ni siquiera basta con vendor_id y hidden KVM: hay que añadir tablas ACPI personalizadas para simular una batería presente y contenta, de forma que el driver no limite la tarjeta.
En servidores Intel es habitual toparse con el RMRR (Reserved Memory Region Reporting), que marca ciertos dispositivos como “no aptos para IOMMU” porque el firmware usa regiones de memoria reservadas. Para algunos dispositivos (sobretodo gráficos integrados y USB internos) esto impide pasarlos a la VM a no ser que uses parches específicos (como el relax-intel-rmrr) o cambies la configuración de BIOS.
Finalmente, hay situaciones en las que el kernel escupe errores de tipo “BAR X: cannot reserve ” o de asignación de BARs al lanzar la VM. A veces se resuelven forzando pci=realloc en el host (y/o el invitado) o reescaneando el bus PCI manualmente antes de arrancar QEMU, especialmente cuando se juega con hotplug de GPUs y controladoras.
Escenarios reales: host Linux, Windows invitado y uso diario
La teoría está muy bien, pero lo interesante es ver cómo se traduce en escenarios de uso concretos. Un caso típico sería un equipo con:
- CPU AMD Ryzen con iGPU (por ejemplo un 8000G o un 9800X3D con gráfica integrada cuando toque).
- Una GPU dedicada potente, tipo RX 7900 o RTX 4080, reservada casi siempre para la VM.
- Doble monitor: uno conectado a la iGPU para el host y otro a la dGPU para la VM, o bien un monitor con múltiples entradas.
En este escenario, Linux corre siempre sobre la iGPU, incluso con Wayland, y la dGPU se vincula a vfio-pci desde el arranque. Cuando levantas el Windows invitado, éste recibe la dGPU en exclusiva y arranca juegos, editores, etc. con un rendimiento extremadamente cercano al nativo. Al apagar la VM, si usas binding temprano, la dGPU seguirá invisible al host; si has optado por scripts de rebind, puedes volver a montarla en Linux para cargas CUDA, Blender, etc.
Otra variante común es en Proxmox VE, donde montas un host sin entorno gráfico, activas IOMMU, añades vfio en /etc/modules, ajustas la línea de kernel según uses GRUB o systemd-boot, y en la GUI de Proxmox vas añadiendo PCI devices a las VMs. Ahí también es frecuente usar 1G hugepages en hosts con mucha RAM, habilitar iommu=pt, jugar con pcie_acs_override solo si es estrictamente necesario y, en caso de AMD, instalar vendor-reset para evitar cuelgues al parar y arrancar VMs con la misma tarjeta.
Combinando todas estas piezas —IOMMU bien habilitado, grupos limpios (o parcheados con ACS), binding correcto de vfio-pci, OVMF, virtio para red/discos, hugepages, pinning y ajustes específicos para NVIDIA/AMD— se puede llegar a un estado en el que el Windows virtualizado se comporta prácticamente como un sistema bare metal, con la ventaja de poder seguir usando Linux al mismo tiempo para tareas de desarrollo, contenedores o servicios de red sin tener que reiniciar ni mantener un dual-boot clásico.
Una vez pillas el punto a todos estos engranajes, el GPU passthrough con VFIO deja de ser ese ritual arcano de foros y wikis dispersas, y se convierte en una herramienta muy potente para exprimir tu hardware al máximo, mezclando lo mejor del mundo Linux con lo que aún sigue atado al ecosistema Windows sin que uno moleste al otro.
