
- smartmontools permite consultar y probar la tecnología SMART de discos y SSD para anticipar fallos físicos.
- smartctl sirve para obtener información detallada, ejecutar tests cortos y largos y revisar logs de errores SMART.
- smartd monitoriza los discos en segundo plano, programa pruebas periódicas y envía alertas ante problemas detectados.
- La vigilancia de atributos clave como sectores reasignados o pendientes, junto con copias de seguridad, reduce mucho el riesgo de pérdida de datos.
Si usas Linux a diario, tarde o temprano te tocará lidiar con un disco duro tocado. Y cuando empiezan los cuelgues raros, lentitud repentina o errores de lectura, tener a mano smartmontools marca la diferencia entre salvar tus datos o quedarte sin nada. Este paquete reúne las utilidades smartctl y smartd, capaces de interrogar al disco sobre su propio estado y avisarte cuando algo empieza a oler a chamusquina.
En este artículo vamos a ver con calma cómo funciona la tecnología SMART (Self-Monitoring, Analysis and Reporting Technology), cómo se instala y se configura smartmontools en distintas distribuciones, qué significan los atributos más importantes y cómo interpretar pruebas cortas, largas y de transporte. La idea es que termines con un procedimiento claro para revisar tus discos, automatizar avisos con smartd y tomar decisiones sensatas sobre cuándo seguir usando un disco y cuándo reemplazarlo sin pensártelo demasiado.
Qué es SMART y por qué te debería importar
La mayoría de discos duros mecánicos y SSD modernos incluyen de fábrica la tecnología SMART, un sistema interno de autocontrol que monitoriza continuamente parámetros críticos del dispositivo: tasas de errores de lectura, sectores reasignados, temperatura, problemas mecánicos, tiempo de spin-up, etc. El objetivo es ofrecer una especie de “termómetro de salud” del disco para anticipar fallos antes de que sean catastróficos. Si trabajas con SSD, conviene también revisar cómo habilitar o deshabilitar el comando TRIM para mantener su rendimiento y vida útil.
SMART almacena internamente una tabla de atributos numerados, cada uno con un valor bruto (RAW_VALUE) y un valor normalizado (VALUE, WORST y THRESH). Si el valor normalizado baja por debajo del umbral THRESH, ese atributo se considera fallido y el disco puede marcar su estado global como problemático. Aun así, es importante tener claro que SMART no es infalible: hay fallos súbitos impredecibles que pueden aparecer sin aviso previo.
Históricamente, los primeros estándares como SFF-8035i y ATA-3/ATA-4 definían tablas internas de hasta 30 atributos, sobre todo orientados a rendimiento y fiabilidad. Con ATA-4 y ATA-5 se amplió la funcionalidad con registros de errores y comandos de autodiagnóstico (tests internos cortos, extendidos, etc.). Aunque hoy en día la tabla de atributos ya no forma parte estricta del estándar, la mayoría de fabricantes la siguen implementando por compatibilidad, de manera que smartmontools puede leerla y descodificarla.
Los fallos que SMART ayuda a detectar son, casi siempre, los fallos predecibles relacionados con el desgaste físico del disco: aumento progresivo de errores de lectura, sectores que se vuelven inestables, problemas mecánicos al arrancar, temperaturas fuera de rango, etc. No puede hacer milagros con fallos impredecibles (subidas de tensión, controladoras defectuosas, golpes violentos), pero aún así es una de las mejores herramientas que tenemos para vigilar la degradación a largo plazo de un disco. Para problemas tras actualizar firmware o drivers NVMe/RAID, consulta cómo resolver errores de almacenamiento.
Punto clave: un informe de estado global SMART “PASSED” no garantiza que el disco no vaya a morir mañana, pero un “FAILED” o un aumento de ciertos atributos (sectores pendientes, offline uncorrectable, reallocated) es un aviso serio de que tienes que respaldar datos cuanto antes.
Qué es smartmontools y qué incluye
El paquete smartmontools agrupa dos herramientas principales:
- smartctl: utilidad de línea de comandos para interactuar directamente con un disco concreto, ver atributos SMART, ejecutar pruebas y consultar registros.
- smartd: demonio que se queda en segundo plano y se encarga de monitorizar periódicamente todos los discos que le indiques, registrar cambios en los logs del sistema y enviar correos o ejecutar scripts cuando detecta problemas.
Está disponible para prácticamente todas las distribuciones GNU/Linux modernas (Slackware, Debian, Ubuntu, SuSE, Fedora, RHEL/AlmaLinux/Rocky, Arch, Gentoo, etc.), y también tiene versiones para otros sistemas como FreeBSD, macOS (Darwin) o Solaris. Incluso en entornos Windows hay frontends gráficos como HDDGuardian que aprovechan la misma lógica de lectura de atributos SMART.
Además de leer y mostrar datos, smartmontools permite ejecutar autodiagnósticos internos del disco (short, long, conveyance, selective), revisar los logs de errores ATA/SCSI y de self-tests, e incluso ajustar ciertos comportamientos como el control de recuperación de errores ATA (muy útil en discos destinados a matrices RAID). En entornos con RAID, es recomendable además conocer cómo sustituir un disco que falla en RAID para completar la estrategia de mantenimiento.
Por defecto, cuando smartd arranca en un sistema Linux típico, revisa los discos cada 30 minutos, intenta detectar cualquier atributo que haya caído por debajo del umbral, mensajes de fallo de salud global, incremento de errores ATA o entradas nuevas en el registro de pruebas. Todo eso lo registra a través de SYSLOG (habitualmente en /var/log/messages o /var/log/syslog) y, si se configura, lo dispara también por correo electrónico o scripts personalizados.
Instalar smartmontools en distintas distribuciones
En la mayoría de distribuciones recientes, smartmontools está en los repositorios oficiales. Sin embargo, en instalaciones minimalistas (por ejemplo, imágenes “Minimal” de AlmaLinux, Rocky o RHEL) puede no venir de serie y tendrás que instalarlo manualmente.
Distribuciones basadas en RHEL: AlmaLinux, Rocky Linux, RHEL
En sistemas modernos basados en RHEL con DNF, puedes instalar el paquete con:
dnf -y install smartmontools
En derivados más antiguos que aún usen YUM (incluidos algunos ALDOS heredados), el comando equivalente sería:
yum -y install smartmontools
Debian, Ubuntu y derivados
En el mundo Debian/Ubuntu y sabores como Linux Mint, puedes instalarlo bien desde el gestor gráfico de paquetes (p. ej., Synaptic) o desde terminal con:
sudo apt install smartmontools
Tras la instalación, tendrás disponibles tanto smartctl como el demonio smartd. Según la distribución, smartd puede activarse automáticamente o quedar deshabilitado hasta que lo configures.
Otras distribuciones: Fedora, Arch, etc.
En Fedora y otras basadas en RPM que ya usan DNF la instalación es igual que en RHEL actual. En Arch Linux y derivadas (Manjaro, EndeavourOS…) se instala con:
sudo pacman -S smartmontools
Si estás en una distribución muy particular o una variante minimalista, siempre puedes descargar el código fuente de smartmontools y compilarlo siguiendo las instrucciones oficiales del proyecto, aunque en la práctica rara vez hace falta llegar a ese extremo.
Activar, iniciar y gestionar el servicio smartd
La supervisión automática la lleva a cabo el demonio smartd. Una vez instalado el paquete, es buena idea activarlo para que se inicie junto al sistema y empiece a vigilar tus discos.
Sistemas con Systemd (AlmaLinux, Rocky, RHEL, Debian, Ubuntu recientes, etc.)
Para habilitar el servicio en el arranque e iniciarlo de inmediato:
sudo systemctl enable --now smartd
Si cambias la configuración de /etc/smartd.conf, tendrás que reiniciar el servicio para aplicar los cambios:
sudo systemctl restart smartd
Y si en algún momento necesitas pararlo (por ejemplo, para pruebas puntuales):
sudo systemctl stop smartd
Sistemas con SysVinit (entornos antiguos tipo ALDOS)
En instalaciones veteranas que aún usan SysVinit, los comandos típicos serían:
Activar en todos los runlevels:
chkconfig smartd on
Iniciar el demonio:
service smartd start
Reiniciarlo tras cambios en la configuración:
service smartd restart
Detenerlo cuando sea necesario:
service smartd stop
Configurar smartd: archivo /etc/smartd.conf
La configuración fina del demonio se hace siempre en /etc/smartd.conf. Al abrirlo por primera vez con tu editor favorito (por ejemplo, vim /etc/smartd.conf), verás unas cuantas líneas de ejemplo y, muy probablemente, una directiva DEVICESCAN al final.
Algo típico suele ser:
# Sample configuration file for smartd...
DEVICESCAN -H -m root
La clave aquí es entender que DEVICESCAN indica a smartd que busque automáticamente todos los discos ATA/SCSI/NVMe y aplique las opciones que le sigan (en el ejemplo, -H -m root) a cada uno. Si esta línea está activa, cualquier otra configuración posterior se ignora. Si quieres controlar exactamente qué se hace con cada dispositivo, lo habitual es comentar esta línea y definir reglas específicas por disco.
Opciones comunes en líneas de configuración
Cada línea de smartd.conf suele tener esta forma:
/dev/sdX OPCIONES
Donde X es la letra del disco (a, b, c…) y las opciones son directivas cortas que le dicen a smartd qué comprobar y cómo avisar. Algunas de las más usadas:
- -a: equivale a “monitorízalo prácticamente todo”: atributos SMART, logs de errores y self-tests.
- -H: mira solo el estado global de salud (“overall-health”). Útil para alertas simples.
- -i: incluye información de identificación (modelo, número de serie, firmware).
- -c: muestra capacidades SMART soportadas por el dispositivo.
- -A: imprime los atributos SMART específicos del fabricante.
- -l error: añade el registro de errores SMART a lo que se vigila.
- -l selftest: incluye el log de auto-pruebas.
- -f: avisa si algún atributo de “uso” o “pre-fail” falla.
- -m correo: dirección de email a la que mandar avisos.
- -M tipo: método de notificación; por ejemplo,
-M exec /ruta/script.shpara ejecutar un script cuando salte una alarma. - -s programación: planifica la ejecución de tests SMART (offline, short, long, conveyance) en ciertos días y horas.
- -t: combinación de
-p -u, es decir, notifica cambios en atributos de prefallo y de uso. - -W i,j,k: supervisa la temperatura: i es el cambio mínimo para notificar, j el umbral de aviso y k el umbral de fallo. Si quieres monitorizar la temperatura del sistema con más detalle, aprende a configurar lm-sensors.
- -I ID: ignora un atributo concreto (muy usado con el 194, temperatura, para no llenar los logs cada pocos minutos).
Ejemplos prácticos de líneas en smartd.conf
Algunos escenarios típicos que se ven mucho en producción:
1. Vigilancia sencilla de /dev/sda y /dev/sdb, revisando estado general, registro de errores y self-tests, y monitorizando cambios en atributos excepto la temperatura:
#DEVICESCAN -H -m root
/dev/sda -H -l error -l selftest -t -I 194
/dev/sdb -H -l error -l selftest -t -I 194
2. Supervisión exhaustiva con control de temperatura y correo cuando algo se tuerce. Aquí se miran todos los atributos menos el 194, se avisa si la temperatura sube o baja 4 ºC o más, y se marcan 45 ºC como advertencia y 55 ºC como fallo serio:
/dev/sda -a -I 194 -W 4,45,55 -m [email protected]
/dev/sdb -a -I 194 -W 4,45,55 -m [email protected]
3. Configuración avanzada para un servidor, desactivando DEVICESCAN y programando pruebas periódicas en un disco concreto, además de ejecutar un script al primer síntoma de problema:
#DEVICESCAN
/dev/sda -H -l error -l selftest -f -s (O/../../5/11|L/../../5/13|C/../../5/15) -m [email protected] -M exec /ruta/al/guion.sh
En este ejemplo, todos los viernes se lanza una prueba corta a las 11:00, una larga a las 13:00 y una de transporte a las 15:00. Si algo falla, el script recibe un informe completo y puede, por ejemplo, enviar más avisos, generar informes o incluso apagar el servidor automáticamente si la situación es crítica.
Uso manual de smartctl: información, pruebas y logs
Aunque smartd te da una vigilancia constante, tarde o temprano querrás lanzar pruebas manuales con smartctl para ver algo concreto o confirmar sospechas. Todas las acciones se hacen sobre un dispositivo concreto, como /dev/sda, /dev/sdb o un NVMe tipo /dev/nvme0n1.
Comprobar soporte SMART e información básica
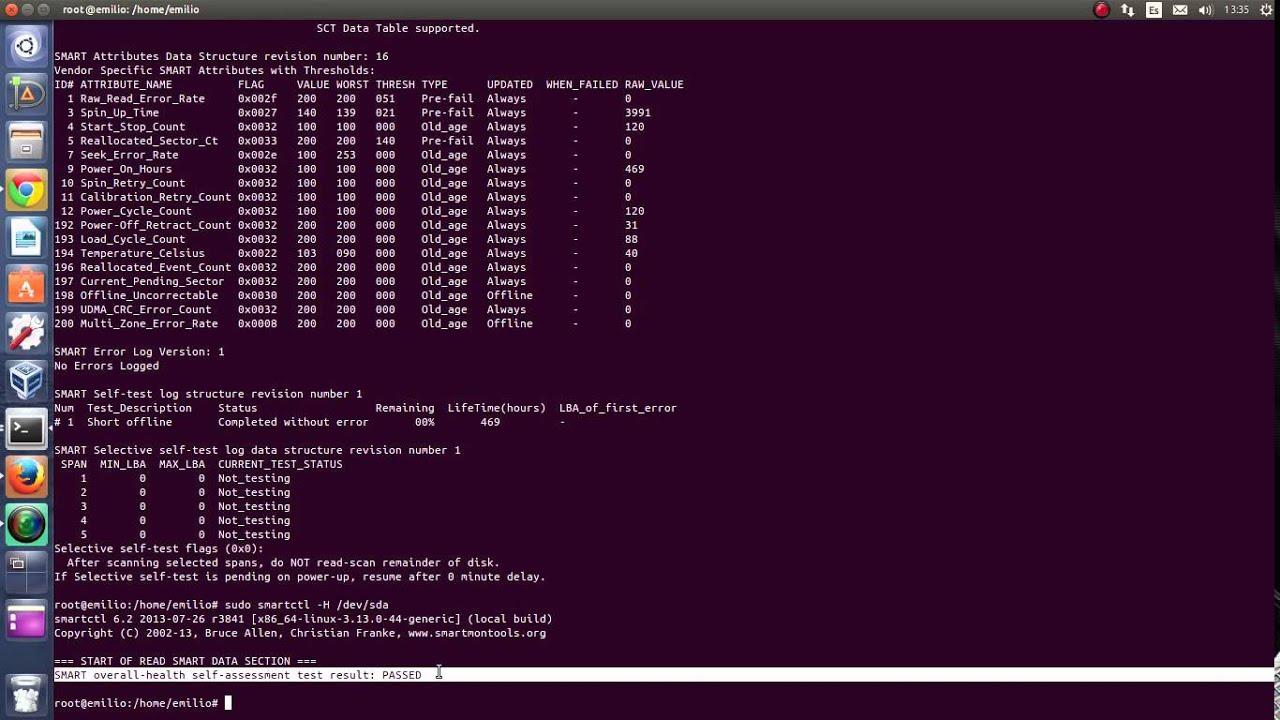
Para verificar si una unidad soporta SMART y ver detalles como modelo, número de serie y firmware:
sudo smartctl -i /dev/sda
En la salida tienes que ver líneas del estilo:
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Si aparece como deshabilitado, puedes activarlo con:
sudo smartctl -s on /dev/sda
Para ver las capacidades de prueba soportadas por el disco (tipos de tests, tiempos estimados, etc.):
sudo smartctl -c /dev/sda
Estado de salud global y reporte detallado
Cuando quieres un diagnóstico rápido, lo más socorrido es pedir el veredicto de salud global:
sudo smartctl -H /dev/sda
Si todo va bien, verás algo en la línea de:
SMART overall-health self-assessment test result: PASSED
Si en cambio aparece FAILED o incluso mensajes de atributos que han rebasado su umbral, no es momento de hacerse el valiente: toca copia de seguridad inmediata y, si el disco está en garantía, ir pensando en RMA.
Para sacar un informe completo con todos los datos SMART, atributos, logs de errores y autodiagnósticos, lo ideal es usar:
sudo smartctl -a /dev/sda | less
También puedes volcar esa información a un fichero de texto para analizarlo con calma o archivarlo:
sudo smartctl -a /dev/sda > ~/smart_sda.txt
Ejecutar pruebas: short, long y conveyance
Los autodiagnósticos SMART se ejecutan dentro del propio disco, sin que el sistema operativo tenga que hacer nada especial. Puedes lanzarlos incluso con el sistema en marcha y las particiones montadas, aunque es normal notar algo de pérdida de rendimiento mientras dura el test. Si prefieres herramientas adicionales para comprobar unidades SSD de forma complementaria, consulta herramientas gratuitas para comprobar la salud de tu SSD.
Las tres pruebas más habituales son:
- Prueba corta (short)
Verifica componentes eléctricos básicos, partes mecánicas y lectura de un subconjunto de sectores. Suele tardar entre 2 y 5 minutos.
sudo smartctl --test=short /dev/sda - Prueba larga o extendida (long/extended)
Escanea prácticamente toda la superficie del disco, leyendo datos y comprobando errores. En discos grandes puede durar horas.
sudo smartctl --test=long /dev/sda - Prueba de transporte (conveyance)
Diseñada para detectar daños físicos provocados por golpes o vibraciones durante el transporte del disco.
sudo smartctl --test=conveyance /dev/sda
Cuando lanzas cualquiera de estos tests, smartctl te dirá que la prueba ha comenzado, cuánto tardará aproximadamente y a qué hora estima que terminará. Si quieres abortar una prueba en curso:
sudo smartctl -X /dev/sda
Consultar resultados y registros de errores
Los resultados de los tests no se ven en el momento de lanzarlos, sino después de que finalicen. Para revisar el registro de self-tests realizados:
sudo smartctl -l selftest /dev/sda
Ahí verás una tabla con los distintos tests ejecutados, su estado (completado con o sin errores), el porcentaje que faltaba cuando se detectó el fallo y, si aplica, el LBA de primer error, que indica en qué dirección lógica apareció el problema.
Para echar un vistazo al registro de errores SMART (errores ATA/SCSI que el disco ha ido guardando):
sudo smartctl -l error /dev/sda
Un log vacío suele indicar buena salud; unas pocas entradas muy antiguas no son preocupantes por sí mismas. Lo que asusta es ver errores frecuentes y recientes, sobre todo si coinciden con lockups del sistema, mensajes de I/O error en dmesg o sectores pendientes que no terminan de resolverse.
Interpretar atributos clave: qué mirar primero
Los informes completos pueden ser kilométricos, así que conviene tener claro qué atributos son especialmente importantes cuando valoras si un disco sigue siendo de fiar o no. Entre los más críticos están:
- Reallocated_Sector_Ct (ID 5)
Cuenta cuántos sectores defectuosos han sido reasignados a un área de reserva. Un RAW_VALUE mayor que 0 indica que ya ha habido problemas físicos y el firmware ha tenido que remapear sectores. Si ese valor sigue creciendo con el tiempo, la degradación es clara. - Current_Pending_Sector (ID 197)
Número de sectores “pendientes”, es decir, aquellos que han dado error de lectura y están a la espera de resolverse en un futuro acceso de escritura. Cualquier valor distinto de 0 es mala señal y, si no baja a 0 tras una prueba larga (o un rellenado controlado de esos sectores), toca desconfiar seriamente del disco. - Offline_Uncorrectable (ID 198)
Sectores defectuosos que no se han podido corregir en pruebas offline. Con RAW_VALUE 0, todo ok; con valores altos, el disco está bastante tocado. - Power_On_Hours (ID 9)
Indica las horas de funcionamiento del disco. Combinado con la tasa media de fallos (MTBF) que da el fabricante puedes estimar, de forma orientativa, la probabilidad de fallo acumulada. No es una ciencia exacta, pero ayuda a poner en contexto un disco que lleva muchos años funcionando 24/7. - Power_Cycle_Count (ID 12)
Número de encendidos y apagados. Algunos discos tienen límites recomendados de ciclos; mientras el valor normalizado VALUE se mantenga entre 100 y 253, la cosa suele ir bien. - Temperature_Celsius (ID 194) o similares
Recoge la temperatura actual y, a veces, mínimos y máximos históricos. Trabajar sistemáticamente por encima del rango recomendado por el fabricante acorta la vida útil del disco de forma notable. - G-Sense_Error_Rate
Mide impactos o aceleraciones bruscas que superan el límite tolerable (típico en portátiles que se caen o reciben golpes). Un VALUE por encima de 100 suele ser aceptable; si empieza a caer, mala pinta. - Raw_Read_Error_Rate
Relacionado con errores de lectura en la superficie. Su interpretación depende mucho del fabricante, pero valores crudos disparados y un VALUE en descenso pueden anticipar problemas serios.
Conviene recordar que el formato exacto de RAW_VALUE y el significado de algunos atributos dependen del fabricante. Smartmontools incorpora una base de datos de modelos para interpretar muchos de ellos automáticamente, y además ofrece la opción -v de smartctl para ajustar manualmente la interpretación de atributos concretos (por ejemplo, que el ID 9 se trate como minutos en lugar de horas).
Tipos de dispositivo y opción -d
En la mayoría de casos recientes, smartctl detecta automáticamente el tipo de dispositivo con -d auto. Aun así, cuando se trabaja con discos SATA detrás de ciertos puentes USB, controladoras RAID o cajas externas exóticas, puede que te encuentres con errores del tipo “Unknown device type” o lecturas incompletas.
En esos casos puedes forzar el tipo de dispositivo, por ejemplo:
- -d ata: SATA conectado directamente como dispositivo ATA.
- -d sat: SATA detrás de un puente (USB-SATA, ciertos RAID de placa, etc.).
- -d scsi: discos SCSI/SAS.
- -d nvme: unidades NVMe modernas.
Un ejemplo típico con un disco SATA en una caja USB que falla en autodetección sería:
sudo smartctl -a -d sat /dev/sdb
Monitorizar el disco en automático con smartd
Ejecutar manualmente smartctl de vez en cuando está bien, pero lo realmente potente es tener smartd vigilando de forma continua. De esta manera, cualquier cambio relevante queda registrado y puedes recibir avisos antes de que el problema se desmadre.
En muchas distribuciones Debian/Ubuntu, además de /etc/smartd.conf encontrarás un archivo /etc/default/smartmontools donde se puede indicar si smartd debe arrancar automáticamente. Lo habitual es asegurarse de que ponga:
start_smartd=yes
y luego iniciar el servicio con:
sudo systemctl start smartd
Si da error, revisa /var/log/syslog o /var/log/messages para ver qué línea de configuración está fallando.
En /etc/smartd.conf puedes tirar de DEVICESCAN con opciones, o bien configurar disco por disco. Un ejemplo típico para discos IDE/SATA convencionales podría ser:
/dev/sda -S on -o on -a -I 194 -m [email protected]
Donde:
- -S on activa el auto-guardado de atributos SMART.
- -o on enciende los tests offline automáticos cada cierto tiempo.
- -a indica que se monitorice todo (atributos, logs de errores, self-tests, etc.).
- -I 194 hace que ignore los cambios en el atributo 194 (temperatura) para que el log no se llene de mensajes triviales.
- -m establece la dirección de correo de destino para las alertas.
Si se trata de un disco SATA que el kernel expone como SCSI (muy habitual), puedes necesitar usar la opción -d sat en la línea, algo así como:
/dev/sda -d sat -S on -o on -a -I 194 -m [email protected]
La flexibilidad de smartd permite además programar tests automáticos con la directiva -s, por ejemplo:
/dev/sda -a -s (S/../.././20|L/../../5/16) -m [email protected]
Con lo que estaría lanzando una prueba corta todos los días a las 20:00 y una prueba larga los viernes a las 16:00, además de enviar avisos por correo si algo sale mal.
Interfaz gráfica: GSmartControl y herramientas en otros sistemas
Aunque la línea de comandos es lo más flexible y guay para automatizar, es cierto que para mucha gente no es lo más cómodo del mundo. Para estos casos existe GSmartControl, una interfaz gráfica para smartctl disponible en muchos repositorios de GNU/Linux.
Con GSmartControl puedes, de forma visual, ver el estado general de cada disco, revisar atributos SMART con colores que marcan riesgo, lanzar tests cortos/largos con un par de clics y revisar los registros de errores sin tener que pelearte con pipes y grep. Es especialmente práctica cuando gestionas equipos de escritorio o quieres revisar rápidamente el parque de discos de una máquina sin meterte a fondo en terminal. Además, para comparar y supervisar discos también puedes usar herramientas como CrystalDiskInfo en entornos Windows.
En entornos Windows, existen aplicaciones como HDDGuardian que hacen un papel similar apoyándose también en la lectura de atributos SMART y ejecución de pruebas internas.
Qué hacer cuando aparecen sectores pendientes o errores graves
Un caso muy típico: el sistema empieza a ir lento, hay bloqueos esporádicos, revisas /var/log/messages o /var/log/syslog y ves líneas repetidas de smartd del tipo:
Device: /dev/sda, 2 Currently unreadable (pending) sectors
Device: /dev/sda, 2 Offline uncorrectable sectors
Además puede que notes que la temperatura sube y baja, y en los atributos aparecen Current_Pending_Sector > 0 y Offline_Uncorrectable > 0. En ese punto lo razonable es:
- Respaldar datos importantes de inmediato, antes de tocar nada más.
- Arrancar, si puedes, desde un disco de rescate o un live USB para no forzar demasiado la unidad afectada.
- Ejecutar una prueba larga SMART sobre el disco para que el firmware intente leer y, si es posible, remapear esos sectores problemáticos:
sudo smartctl -t long /dev/sda - Esperar el tiempo indicado por smartctl, reiniciar si procede y revisar el log de self-tests y de errores.
La prueba extendida fuerza al disco a intentar leer y, en algunos casos, escribir sobre los sectores problemáticos. Si consigue remapearlos con éxito, el contador de sectores pendientes debería bajar, mientras que el de reasignados aumentará. Si, en cambio, los pendientes no desaparecen o siguen subiendo con el tiempo, el disco está claramente al final de su vida útil y conviene sustituirlo cuanto antes.
En muchos casos, si el disco todavía está en garantía, las propias herramientas de diagnóstico oficiales de cada fabricante (PowerMax, Drive Fitness Test, etc.) se basan en los mismos principios y, si detectan errores de este tipo, suelen generar un código de fallo que puedes usar para tramitar un reemplazo. Si trabajas con NAS en RAID-1, revisa cómo sustituir un disco en NAS con RAID-1.
Al final, la regla de oro es sencilla: si SMART empieza a cantar, sobre todo con atributos de sectores pendientes, offline uncorrectable o reallocated en aumento, no merece la pena jugar con fuego. Respaldos, clonación si procede y disco nuevo.
Usar smartmontools te da una ventaja enorme frente a ir “a ciegas”: puedes vigilar la salud de tus discos con bastante precisión, programar pruebas regulares y montar un sistema de alertas por correo o scripts que te avise cuando algo empieza a torcerse. No sustituye a las copias de seguridad (eso nunca), pero sí te ayuda a anticiparte al desastre y a decidir con datos en la mano cuándo un disco sigue siendo aceptable para cierto uso y cuándo es hora de jubilarlo antes de que te deje tirado en el peor momento.
