
- El Qualcomm Cloud AI 100 Ultra es un acelerador ASIC de 7 nm optimizado para inferencia de IA en centros de datos y entornos de borde, con una relación rendimiento/consumo muy superior a GPU y FPGA genéricas.
- En comparativas con NVIDIA A100, puede ejecutar ciertos LLM de 70B parámetros con una sola tarjeta, logrando reducciones de consumo de hasta 20 veces y, en modelos más pequeños, diferencias de hasta 35 veces menos energía.
- Ofrece amplio soporte de software (PyTorch, TensorFlow, Keras, Glow, ONNX) y herramientas como Qualcomm AI Inference Suite, facilitando el despliegue de LLM, NLP y visión por computador en plataformas como la NRP o nubes comerciales.
- Se adapta a múltiples casos de uso, desde chatbots y copilots hasta visión artificial y conducción autónoma, con opciones de despliegue bare-metal y servicios gestionados que permiten escalar de forma granular.

La inteligencia artificial en la nube está viviendo un momento de auténtica revolución y, en ese contexto, el Qualcomm Cloud AI 100 Ultra se ha convertido en uno de los aceleradores de inferencia más llamativos del mercado. No está pensado para entrenar modelos gigantes desde cero, sino para algo igual de crítico: desplegar modelos ya entrenados, sobre todo grandes modelos de lenguaje (LLM) y aplicaciones de visión por computador, con el máximo rendimiento posible y consumiendo muy poca energía.
Este enfoque tiene todo el sentido del mundo en centros de datos y plataformas de investigación donde cada vatio cuenta. Frente al dominio habitual de las GPU de NVIDIA en inteligencia artificial, el Cloud AI 100 Ultra propone una arquitectura específica para inferencia, con una relación rendimiento/consumo muy agresiva y una capacidad de escalado muy fina, lo que permite ajustar mucho mejor los recursos de hardware a las necesidades reales de cada modelo.
Qué es exactamente el Qualcomm Cloud AI 100 Ultra
El Qualcomm Cloud AI 100 Ultra forma parte de la familia de aceleradores Cloud AI 100, chips tipo ASIC diseñados desde cero para ejecutar inferencia de modelos de IA en centros de datos y entornos de borde. No son GPU genéricas ni FPGA reconfigurables, sino circuitos optimizados para operaciones típicas de redes neuronales, lo que les permite reducir consumo y aumentar la eficiencia frente a soluciones más generalistas.
En su lanzamiento, Qualcomm destacó que su plataforma Cloud AI 100 proporciona hasta diez veces más rendimiento por vatio que las mejores alternativas de inferencia IA del momento. Esta ventaja viene en parte de la propia arquitectura específica para IA y, en parte, del uso de un nodo de fabricación avanzado de 7 nm, que mejora notablemente la eficiencia energética frente a procesos más antiguos.
Otra característica importante es que esta gama de aceleradores está orientada desde el principio a los centros de datos y a dispositivos de red situados en el borde de la infraestructura, donde se necesitan muchos inferences por segundo pero con un presupuesto de energía limitado. De este modo, se posiciona como una opción muy interesante para servicios de IA en la nube y para tareas que necesitan baja latencia cerca del usuario final.
Al ser un ASIC, el Cloud AI 100 Ultra renuncia a la flexibilidad extrema de una FPGA a cambio de una reducción de consumo aún mayor y de un rendimiento más predecible en las cargas típicas de IA. Qualcomm ha priorizado un uso muy concreto: la inferencia, es decir, poner en producción modelos ya entrenados, en vez de cubrir también escenarios de entrenamiento pesado como hacen las GPU orientadas a HPC.

Arquitectura y eficiencia energética
Una de las claves del Qualcomm Cloud AI 100 Ultra es su arquitectura centrada en la eficiencia por vatio. Según la propia Qualcomm, la familia Cloud AI 100 fue concebida con el objetivo específico de maximizar el rendimiento de inferencia manteniendo el consumo lo más bajo posible, una prioridad absoluta en centros de datos modernos donde la factura eléctrica y la refrigeración son factores críticos.
En los primeros modelos Cloud AI 100, la compañía ya presumía de estar muy por encima de las GPU y FPGA disponibles en ese momento en relación potencia-consumo. El uso de un proceso litográfico de 7 nm permite incrementar la densidad de transistores y reducir las pérdidas, algo que tiene un impacto directo tanto en el rendimiento sostenido como en la disipación térmica.
Más allá de los datos de marketing, recientes análisis independientes dan cifras muy reveladoras. En un estudio comparativo dentro de la Plataforma Nacional de Investigación (NRP), se analizó el comportamiento del Qualcomm Cloud AI 100 Ultra (referido como QAic) frente a configuraciones con GPU NVIDIA A100 para la inferencia de grandes modelos de lenguaje. El foco se puso en tres aspectos: rendimiento bruto, rendimiento por vatio y capacidad de escalado de hardware.
En ese trabajo se desplegaron 12 modelos de lenguaje abiertos, con tamaños desde 124 millones hasta 70.000 millones de parámetros, utilizando el framework vLLM, lo que permite una comparación bastante homogénea entre plataformas. Los resultados muestran que el QAic alcanza una eficiencia energética muy competitiva, con ventajas claras en determinados tamaños de modelo y escenarios.
Lo más llamativo es que, en algunos modelos de 70.000 millones de parámetros, se puede trabajar con una sola tarjeta QAic en lugar de las 8 GPU A100 necesarias en la configuración de referencia. En esas condiciones, el consumo medido fue de unos 148 W para el QAic frente a casi 2.983 W para el conjunto de 8 A100, una diferencia de aproximadamente 20 veces menos energía para una tarea comparable de inferencia.

Comparación con GPU NVIDIA A100 y escalabilidad
El Qualcomm Cloud AI 100 Ultra no pretende sustituir a las GPU en todo, pero sí planta cara en el terreno específico de la inferencia de LLM y otros modelos ya entrenados. El estudio mencionado compara directamente QAic con configuraciones de 4 y 8 GPU NVIDIA A100, que son referencias absolutas en computación acelerada para IA.
Uno de los puntos fuertes del QAic es su granularidad de hardware. Mientras que ciertos modelos grandes requieren aglutinar varias GPU A100 para alcanzar la capacidad necesaria, el Cloud AI 100 Ultra puede ejecutar algunos LLM de 70B parámetros con una única tarjeta. Esto simplifica el despliegue, reduce el coste total de propiedad y permite escalar por nodos de forma más fina según la carga de trabajo.
En términos de energía, las diferencias son incluso más contundentes en modelos pequeños y medianos. Para ciertos modelos de menor tamaño, un solo dispositivo QAic puede operar con consumos del orden de 36 W, mientras que la configuración de referencia con 4 GPU A100 supera con facilidad los 1.200 W. Es decir, hay escenarios en los que el ahorro energético se acerca a un factor x35, manteniendo un rendimiento adecuado para el servicio.
Esto tiene implicaciones directas en plataformas como la NRP y, en general, en cualquier servicio de IA en la nube: se pueden servir más peticiones por unidad de energía disponible. En centros de datos con limitaciones de potencia contratada o con objetivos estrictos de sostenibilidad, esa diferencia puede marcar la viabilidad o no de determinados proyectos de IA generativa a gran escala.
Además, el QAic está pensado para funcionar de manera eficiente tanto en despliegues pequeños como en grandes clústeres. Su escalabilidad de hardware permite empezar con unas pocas tarjetas y ampliar la infraestructura progresivamente, sin necesidad de saltos bruscos de inversión ni de reconfiguraciones masivas del sistema.
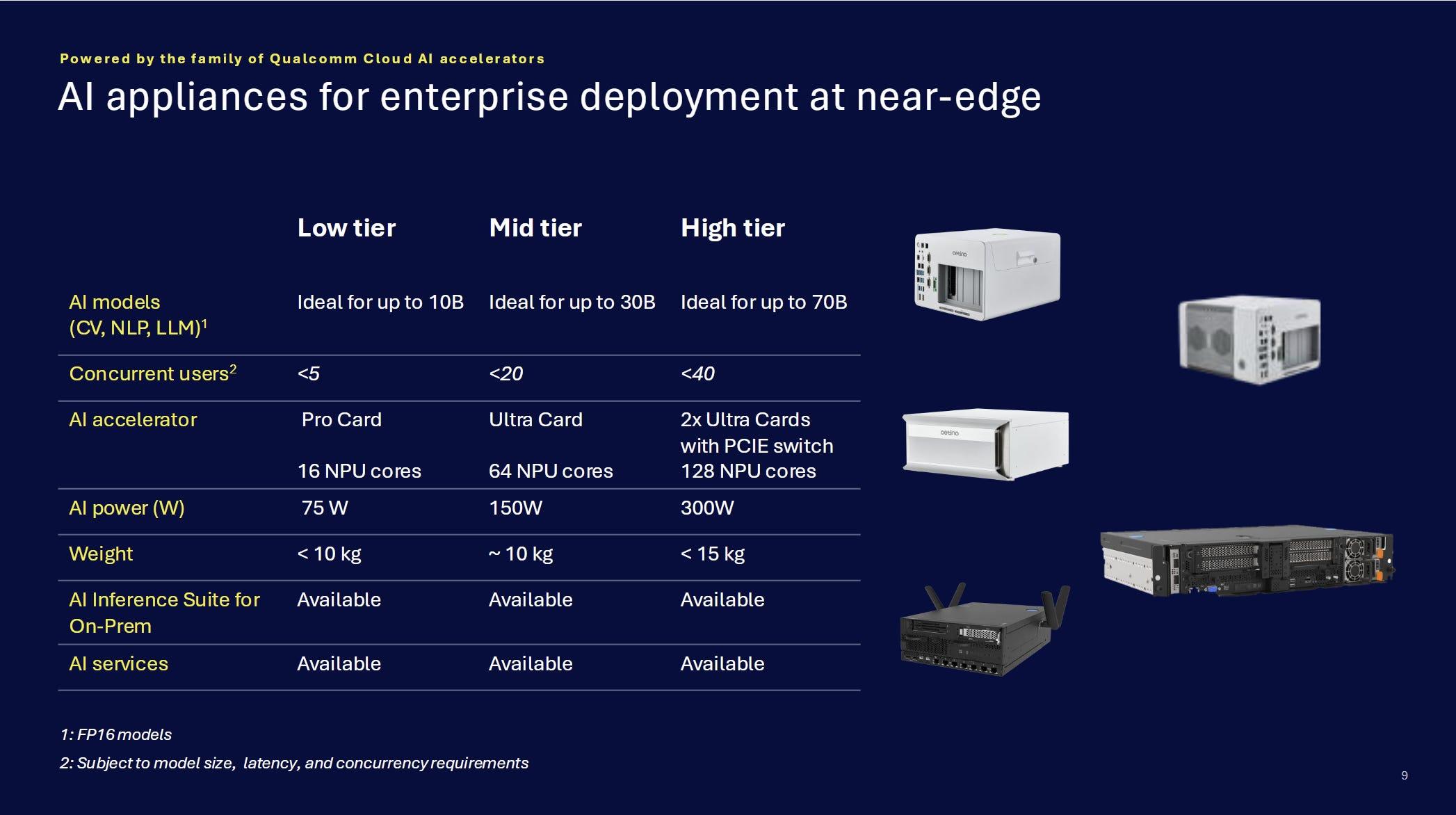
Compatibilidad de software y ecosistema de desarrollo
Un acelerador potente sirve de poco si luego resulta un infierno integrarlo. Por eso, una parte esencial de la propuesta de Qualcomm con la familia Cloud AI 100 es su compatibilidad con los principales frameworks y estándares del ecosistema IA. Desde el inicio, la compañía ha apostado por soportar entornos ampliamente usados por desarrolladores y científicos de datos.
Entre los marcos de trabajo admitidos se encuentran PyTorch, TensorFlow, Keras, Glow y ONNX, lo que facilita portar modelos existentes o desplegar nuevos desarrollos sin tener que reescribir todo el pipeline. El soporte de ONNX, en particular, es muy útil para mover modelos entre plataformas manteniendo un formato intermedio estándar.
Además de la compatibilidad de bajo nivel, Qualcomm ofrece herramientas específicas en forma de Qualcomm AI Inference Suite, un conjunto de utilidades y librerías pensado para simplificar la puesta en producción de modelos de IA sobre su hardware. Sobre esta base se construyen soluciones como el “Inference Cloud powered by Qualcomm”, donde se proporcionan aplicaciones y agentes listos para usar que aceleran el desarrollo y despliegue de servicios basados en IA generativa.
Otro aspecto relevante es la relación del Cloud AI 100 con las redes de nueva generación. Qualcomm, muy activa en el ámbito del 5G, ha diseñado estos aceleradores pensando en escenarios de baja latencia y alta conectividad, lo que permite integrarlos en arquitecturas donde la inferencia se reparte entre la nube central y nodos de borde conectados mediante enlaces 5G.
En la parte de acompañamiento software, la compañía también proporciona bibliotecas específicas y documentación técnica para que integradores y desarrolladores puedan exprimir las capacidades del hardware. Esto incluye desde herramientas de optimización de modelos hasta utilidades de monitorización, muy útiles para gestionar la capacidad en centros de datos grandes.
Casos de uso del Qualcomm Cloud AI 100 Ultra
El Qualcomm Cloud AI 100 Ultra está especialmente orientado a la inferencia de modelos de IA en producción, con un foco muy claro en tres grandes familias de aplicaciones: grandes modelos de lenguaje, procesamiento de lenguaje natural en general y visión por computador. A partir de ahí, se abren muchas posibilidades prácticas tanto en empresas como en investigación.
En el ámbito de los LLM, el Cloud AI 100 Ultra permite desplegar modelos de código abierto como GPT-2 y sus variantes, BERT y derivados, así como otros modelos generativos y de comprensión de texto que se usan a diario en asistentes, sistemas de búsqueda avanzada o herramientas de análisis de documentos. La combinación de alta eficiencia con soporte para modelos grandes y pequeños lo hace adecuado tanto para pruebas de concepto como para servicios de gran escala.
Entre los usos típicos de estos modelos se encuentran tareas de generación de código, asistentes de programación, automatización del desarrollo web, chatbots y sistemas de atención al cliente para comercio electrónico, resumen automático de documentos y correos, asistentes tipo “copilot” para reuniones, traducción automática y, en general, cualquier sistema que mejore el acceso a información y mercados en distintos idiomas.
Fuera del puro procesamiento de texto, el Cloud AI 100 Ultra también está preparado para una amplia gama de modelos de visión por computador: clasificación de imágenes, detección de objetos, segmentación semántica, estimación de pose y detección de rostros, entre otros. Estas capacidades son clave en campos como la videovigilancia inteligente, el análisis de contenido multimedia o los sistemas de recomendación basados en imagen.
Otro terreno donde estos aceleradores tienen mucho que decir es la conducción autónoma y los sistemas avanzados de asistencia al conductor. La posibilidad de ejecutar múltiples modelos de percepción en paralelo, con un consumo muy contenido, encaja bien con la necesidad de procesar en tiempo real las señales de cámaras, radares y otros sensores, ya sea en el propio vehículo o en la infraestructura conectada.
En el sector sanitario, la combinación de IA en la nube y eficiencia energética permite desplegar modelos de diagnóstico asistido, análisis de imágenes médicas y sistemas de apoyo a la decisión clínica sin disparar los costes de operación. La baja latencia y la capacidad de escalar por tarjetas hace viable ofrecer estos servicios a muchos centros médicos desde plataformas compartidas.
Entornos de despliegue y opciones personalizadas
Para que esta tecnología llegue realmente a empresas y organizaciones, es clave contar con socios que ofrezcan infraestructura lista para usar. En este sentido, proveedores como Cirrascale ponen a disposición soluciones basadas en Qualcomm Cloud AI 100 Ultra en modalidad bare-metal, lo que permite integrar a fondo los aceleradores con los flujos de trabajo DevOps de cada cliente.
Este tipo de despliegues bare-metal se diferencia de las soluciones puramente virtualizadas en que el cliente tiene control directo sobre el hardware, pudiendo afinar al máximo la configuración, la orquestación de cargas de trabajo y el mantenimiento. Es una opción muy valorada en entornos donde se necesitan garantías estrictas de rendimiento y aislamiento.
La combinación de hardware específico y opciones de personalización facilita que grandes organizaciones puedan crear plataformas internas de inferencia optimizadas para sus modelos, sin depender por completo de servicios de terceros ni de infraestructuras genéricas. Esto resulta especialmente atractivo en sectores regulados o con requisitos de confidencialidad altos.
Por otro lado, el enfoque basado en la Qualcomm AI Inference Suite y el “Inference Cloud powered by Qualcomm” permite a empresas con menos recursos técnicos aprovechar la potencia del Cloud AI 100 Ultra a través de servicios gestionados. En estos casos, se ofrecen agentes, APIs y aplicaciones preconfiguradas para acelerar el despliegue de soluciones de IA generativa y análisis avanzado.
En suma, la plataforma está pensada para encajar tanto en entornos HPC y de investigación (como la NRP) como en nubes públicas y privadas, con diferentes niveles de control y de abstracción según las necesidades del cliente final y su equipo técnico.
Con todo lo anterior, el Qualcomm Cloud AI 100 Ultra se consolida como una apuesta muy sólida para la inferencia de modelos de IA modernos, especialmente LLM y visión por computador, destacando por su eficiencia energética, su capacidad de ejecutar modelos grandes con muy pocas tarjetas, su compatibilidad con los marcos de trabajo más usados y la variedad de opciones de despliegue disponibles. Para organizaciones con recursos limitados o con objetivos de sostenibilidad ambiciosos, representa una alternativa real a las GPU tradicionales en el terreno de la IA en producción.
