
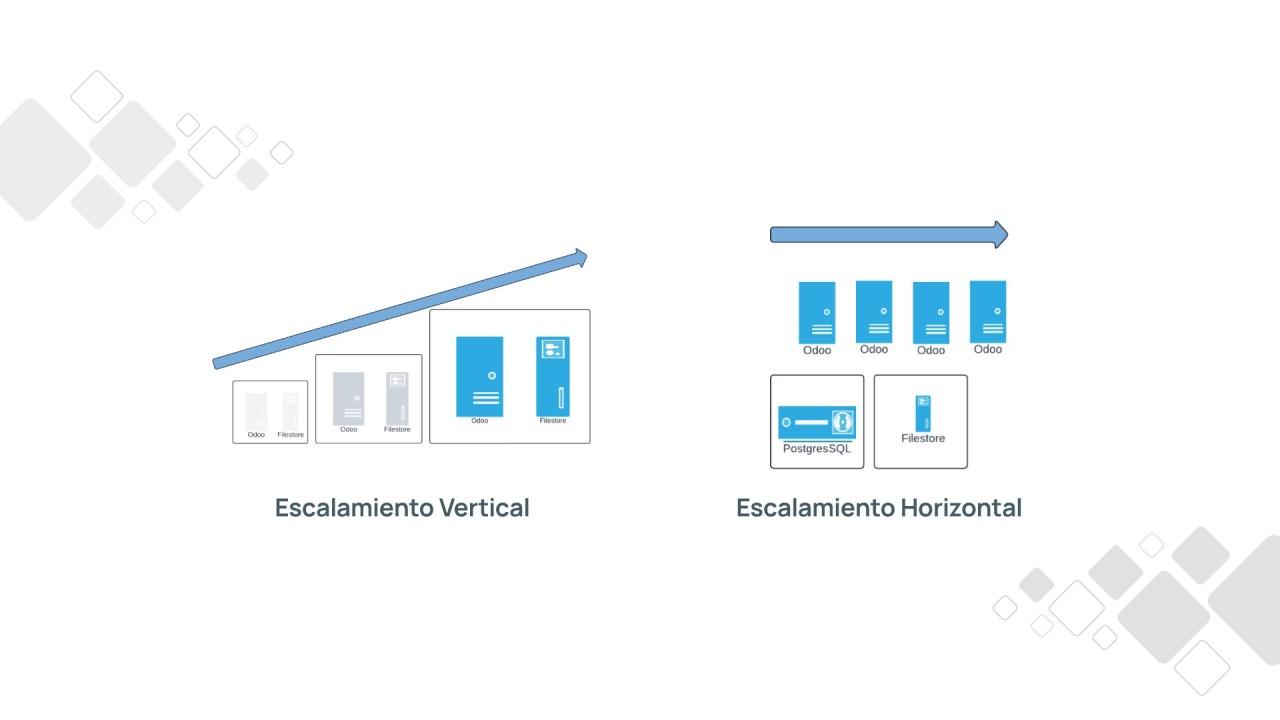
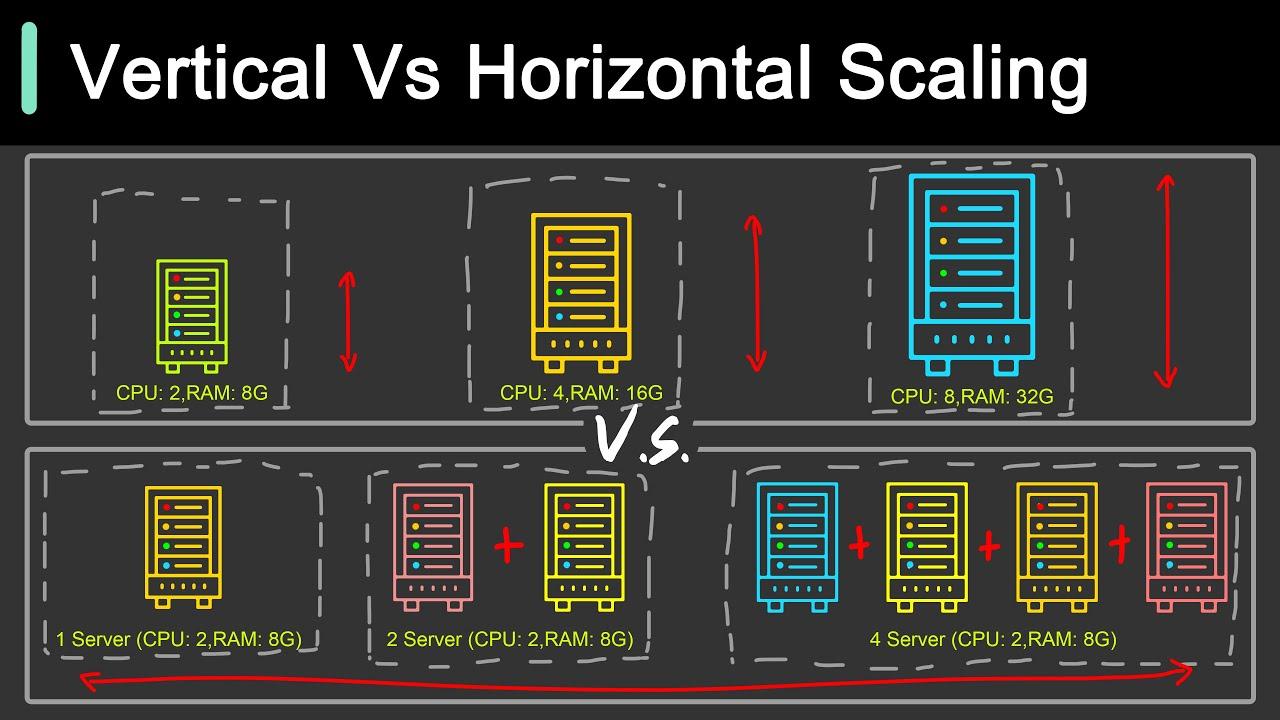
- El escalado vertical refuerza un único nodo con más recursos, es simple de aplicar pero está limitado por el hardware y concentra el riesgo en un único punto de fallo.
- El escalado horizontal añade nodos y distribuye la carga, ofrece alta disponibilidad y crecimiento casi ilimitado, a costa de mayor complejidad y necesidad de arquitecturas stateless.
- El escalado lógico organiza servicios y datos (microservicios, sharding, particiones por SLA) para eliminar cuellos de botella y permitir escalar cada parte de forma independiente.
- En memoria NAND, el escalado lateral, vertical 3D y arquitecturas como CBA aumentan densidad, rendimiento y eficiencia, sosteniendo las necesidades de las arquitecturas distribuidas modernas.
Cuando hablamos de escalabilidad casi todo el mundo piensa en “poner más máquinas” o “meter más RAM”, pero la realidad es bastante más matizada, sobre todo si cruzamos el mundo de las arquitecturas de software (escalado vertical, horizontal y lógico) con el de la memoria NAND y sus arquitecturas en 2D, 3D e in-memory. Entender cómo encajan todas estas piezas es clave para diseñar sistemas que aguanten crecimientos fuertes de tráfico, de datos y de usuarios sin morirse en el intento.
En este artículo vamos a hilarlo todo: qué es el escalado vertical, horizontal y lógico en aplicaciones y servidores, cómo se combinan con arquitecturas distribuidas modernas (microservicios, Kubernetes, nubes públicas) y cómo se relacionan con el memoria NAND, donde entran en juego tecnologías como celdas 3D, apilados verticales y enfoques avanzados como CBA (CMOS Bonded to Array). La idea es verlo con calma, en castellano de la calle, pero sin dejarnos ni una sola pieza técnica importante.
Qué significa realmente escalar un sistema

Escalar un sistema no es solo “poner más hierro”, sino la capacidad de que una aplicación o plataforma soporte un aumento creciente de usuarios, peticiones y datos sin degradar el rendimiento ni la calidad de servicio. Esto implica tanto decisiones de arquitectura de software como de hardware y red.
En la práctica hablamos de dos grandes familias de estrategias: el escalado vertical (scale-up), donde reforzamos un solo nodo, y el escalado horizontal (scale-out), donde añadimos más nodos y repartimos la carga. A eso se suma el escalado lógico, que tiene que ver con cómo dividimos y organizamos lógicamente servicios, datos y flujos de trabajo para que ese crecimiento sea sostenible.
Además, cuando bajamos a nivel de hardware de almacenamiento, especialmente en memoria NAND, aparece otro tipo de escalado: el escalado de arquitectura en memoria, que incluye el paso de celdas 2D a 3D, el aumento de capas apiladas, el escalado lateral (en superficie) y vertical (en altura), junto a técnicas como CBA que separan matriz de celdas y lógica periférica para optimizar cada parte por separado.
La clave es entender que todos estos escalados se combinan: puedes tener una aplicación con escalado horizontal en la nube, corriendo sobre discos SSD NAND con apilado vertical 3D, mientras aplicas escalado lógico mediante microservicios y particionado de datos. Si uno de los niveles se queda corto, aparecerá el cuello de botella.
Escalado vertical (scale-up) en software y servidores
El escalado vertical es el más intuitivo: coges un servidor y lo haces más potente. Más CPU, más RAM, más almacenamiento, quizá una tarjeta de red mejor, o en la nube cambias una instancia pequeña por otra con muchos más recursos.
Ejemplos típicos de escalado vertical serían ampliar la RAM de un servidor de 16 GB a 64 GB, pasar de 4 a 32 cores, sustituir discos mecánicos por SSD NVMe o cambiar una instancia de AWS de tipo t3.medium a una t3.xlarge. La aplicación sigue siendo la misma, pero corre sobre una máquina más “tocha”.
La gran ventaja del scale-up es que la aplicación casi no se entera: no tienes que rediseñar la arquitectura, ni introducir balanceadores de carga, ni pensar en coherencia entre nodos. Simplemente mejoras el “musculito” de la misma máquina y listo.
Por eso el escalado vertical suele ser ideal para aplicaciones monolíticas heredadas, bases de datos relacionales clásicas (MySQL, PostgreSQL, SQL Server) o sistemas que no fueron concebidos para trabajar en clúster. También es muy útil en workloads intensivos en CPU o GPU como renderizado o cálculo científico.
Cómo funciona el escalado vertical en la práctica
En la práctica, escalar verticalmente consiste en mejorar el hardware de un único nodo: subir de gama el servidor dedicado, añadir más módulos de memoria, cambiar a CPUs con más cores o mayor frecuencia, ampliar el almacenamiento o migrar toda la aplicación a una máquina nueva más potente.
En entornos cloud el proceso es aún más sencillo: basta con cambiar el tipo de instancia o plan de servidor (por ejemplo en Amazon RDS, Google Cloud SQL o servidores cloud de proveedores europeos). Muchas veces incluso puedes hacer esa ampliación con tiempos de parada muy controlados o casi nulos si el proveedor lo soporta.
El concepto se parece a ampliar un PC doméstico: si tu equipo se queda corto para editar vídeo, le metes más RAM, un SSD y, si hace falta, cambias el procesador. El software no cambia, pero la experiencia de uso mejora porque ahora la máquina aguanta más carga de trabajo.
Ventajas del escalado vertical
- Implementación sencilla: gestionar un solo servidor es más fácil que montar y mantener un clúster completo de máquinas.
- Pocos cambios en la aplicación: no exige rediseñar la arquitectura ni que la app sea stateless o distribuida.
- Baja latencia interna: al estar todo en la misma máquina, no existe overhead de red entre nodos.
- Buena relación esfuerzo/beneficio en fases iniciales: para proyectos pequeños o en sus primeros meses, aumentar recursos de un nodo suele ser la opción más rentable.
Desventajas y límites del escalado vertical
El principal problema del escalado vertical es que está ligado a límites físicos y económicos. Llega un momento en el que ya no puedes poner más RAM, o la siguiente CPU compatible es desproporcionadamente cara para el salto de rendimiento que aporta.
- Límite físico de crecimiento: un único servidor solo puede crecer hasta donde permite su placa base y el catálogo del fabricante.
- SPOF (Single Point of Failure): si esa máquina cae, se cae todo el servicio, salvo que tengas una estrategia de failover bien montada.
- Posible downtime en upgrades: muchas ampliaciones requieren parar el servidor, aunque se intente minimizar ese impacto.
- Coste creciente: el hardware de gama muy alta suele dispararse en precio, con una mejora marginal de rendimiento.
Para mitigar parte de estos riesgos, algunas empresas combinan escalado vertical con failover: un servidor secundario espejo, en standby, que asume la carga si el primario revienta. Esto mejora la alta disponibilidad, pero duplica costes de infraestructura y complica la administración.
Escalado horizontal (scale-out) y arquitecturas distribuidas
El escalado horizontal ataca el problema de otra forma: en vez de hacer una máquina más grande, añades más máquinas (nodos), todas trabajando juntas como un clúster distribuido. Cuando falte capacidad, metes otro nodo en la ecuación y repartes tráfico.
La idea es “muchos autobuses pequeños en lugar de uno gigante”. En vez de un servidor enorme manejando millones de peticiones, tienes varios servidores relativamente modestos detrás de un balanceador de carga, compartiendo la presión de trabajo.
Para que esto funcione necesitas componentes extra: balanceadores (Nginx, HAProxy, AWS ALB, etc.), mecanismos de sincronización de estado (Redis, bases de datos distribuidas) y, muy importante, aplicaciones diseñadas para ser stateless o para delegar el estado en sistemas compartidos.
Cómo se implementa el escalado horizontal
En un esquema típico de escalado horizontal tienes un cluster de servidores web o de aplicación, todos sirviendo la misma app. Un balanceador recibe las peticiones de los usuarios y decide a qué nodo se las envía, siguiendo políticas de round-robin, least-connections, afinidad, etc.
Si la carga aumenta, añades un nuevo nodo al cluster. El balanceador lo mete en el “pool” y empieza a enviarle tráfico. Si un nodo falla, se marca como no saludable y deja de recibir peticiones mientras el resto siguen atendiendo al usuario sin que este note nada.
En la nube pública este patrón es omnipresente. Servicios como Auto Scaling Groups en AWS, escalado de instancias en Azure o GCP, y orquestadores como Kubernetes permiten crear sistemas que se autoajustan a la demanda, añadiendo o retirando nodos según CPU, memoria o métricas personalizadas.
Ventajas del escalado horizontal
- Capacidad de crecimiento casi ilimitada: mientras puedas seguir añadiendo nodos, la plataforma puede seguir aumentando su capacidad.
- Alta disponibilidad y tolerancia a fallos: si un nodo se rompe, los demás absorben la carga; el sistema es intrínsecamente más resiliente.
- Coste más lineal: puedes usar hardware commodity y pagar “a medida que creces”, en vez de invertir de golpe en un servidor monstruoso.
- Elasticidad: es fácil subir y bajar capacidad en función de picos de tráfico (campañas, Black Friday, etc.).
Desventajas y complejidad del escalado horizontal
La cara B es la complejidad. Diseñar, desplegar y mantener sistemas distribuidos no es trivial, sobre todo si tu aplicación no fue concebida para ello desde el inicio.
- Mayor dificultad de configuración y operación: hay que gestionar balanceadores, networking, certificados, observabilidad, logging distribuido, etc.
- Gestión de sesiones y estado: mantener sesiones de usuario en múltiples nodos exige usar mecanismos externos (Redis, JWT, sticky sessions…).
- Overhead de red: cada salto entre nodos introduce latencia y posibles puntos de fallo.
- Requiere diseño específico: muchas apps legacy directamente no soportan bien este enfoque sin una refactorización profunda.
Escalado lógico: dividir para poder crecer
Cuando hablamos de escalado lógico nos referimos a cómo segmentamos funcionalmente y por datos nuestro sistema para poder aplicar mejor el escalado vertical y horizontal. Es la parte de “arquitectura” pura: microservicios, sharding, particionado por SLA o tipo de cliente, etc.
Una arquitectura distribuida débilmente acoplada permite escalar cada componente de forma independiente, eliminando cuellos de botella. En lugar de un producto monolítico, tienes un conjunto de servicios o productos de software que cooperan, pero pueden desplegarse y ampliarse de forma autónoma.
Esto habilita estrategias muy finas de escalado: puedes dar más capacidad a los servicios que usan los clientes “oro” o a las API más demandadas, sin tocar el resto. El resultado es un uso mucho más eficiente de la infraestructura, sobre todo en nubes públicas donde pagas por lo que consumes.
La combinación de escalado lógico + horizontal es la base de muchas arquitecturas modernas de microservicios y contenedores, donde cada microservicio se puede escalar independientemente (más réplicas de un pod en Kubernetes, por ejemplo) según su propia carga.
Escalado de arquitectura en memoria NAND: vertical, lateral y lógica
Hasta ahora hemos hablado de servidores y aplicaciones, pero el escalado también ocurre a nivel de almacenamiento físico, especialmente en memorias NAND usadas en SSD, móviles y multitud de dispositivos.
La NAND tradicionalmente escalaba “lateralmente” reduciendo el tamaño de las celdas en 2D para meter más bits por milímetro cuadrado. Sin embargo, eso llega a un punto en el que la fiabilidad y las interferencias se vuelven un problema serio.
Para seguir aumentando densidad de bits, la industria adoptó el escalado vertical con NAND 3D: se apilan múltiples capas de celdas unas encima de otras, de forma parecida a construir un edificio en altura en lugar de extenderse en horizontal.
Además del apilado vertical, han aparecido arquitecturas avanzadas como la tecnología CBA (CMOS Bonded to Array), donde la matriz de celdas y la lógica periférica CMOS se fabrican por separado, cada una en su proceso óptimo, y luego se unen (bonding) en oblea.
Qué aporta el escalado de arquitectura en NAND
Separar celda y periférico mediante CBA permite optimizar independientemente la fiabilidad de la celda (retención, ciclos de programa/borrado) y la velocidad de E/S y lógica de control. Se reduce la necesidad de compromisos entre densidad, rendimiento y durabilidad.
Esta aproximación se traduce en una mejora notable de eficiencia energética, mayores velocidades de entrada/salida, mejor densidad de bits, reducción de costes por bit almacenado y un impacto positivo en sostenibilidad, al exprimir mejor cada oblea producida.
En resumen, en el nivel de memoria física también tenemos un juego entre escalado lateral (más celdas por superficie), vertical (más capas apiladas) y lógico/arquitectural (cómo organizamos celdas, bloques, páginas, controladores y periféricos para maximizar el rendimiento y la fiabilidad).
Relación entre escalado lógico, vertical, horizontal y NAND
Puede parecer que el mundo del software (vertical/horizontal/lógico) y el de la memoria NAND van por caminos separados, pero en realidad están íntimamente relacionados: el techo físico del hardware condiciona qué podemos hacer a nivel de arquitectura de sistemas.
Si el almacenamiento subyacente escala bien (más densidad, mejor latencia, mayor ancho de banda), las arquitecturas horizontales y lógicas pueden cachear más, procesar más datos en memoria y reducir cuellos de botella en I/O. Esto es vital en entornos de Big Data, analítica y servicios web de alto tráfico.
Por otro lado, un escalado lógico bien diseñado puede compensar limitaciones físicas de la NAND: particionar datos calientes en SSD rápidos y datos fríos en capas más baratas, usar cachés distribuidas, o distribuir la carga de escritura para alargar la vida útil de los dispositivos.
En arquitecturas modernas de nube e hiperconvergencia, esta relación es todavía más estrecha: los bloques preempaquetados de infraestructura incluyen cómputo, red y almacenamiento (NAND 3D en muchos casos) en un solo nodo, y el proveedor escala horizontalmente añadiendo nodos hiperconvergentes.
Escalado en la nube pública, hiperconvergencia y servicios distribuidos
Ejemplos clave son los Auto Scaling Groups de AWS para instancias EC2, los servicios de Kubernetes gestionado (EKS, AKS, GKE) y las plataformas serverless (AWS Lambda, Azure Functions), que escalan funciones prácticamente a cero o a miles de ejecuciones concurrentes sin que el desarrollador tenga que gestionar máquinas.
Al mismo tiempo, muchos CSP utilizan infraestructuras hiperconvergentes: nodos que integran computación, memoria, red y almacenamiento en bloque, listos para escalar en “bloques” predefinidos. Para los departamentos de TI acostumbrados a arquitecturas tradicionales, este modelo resulta más fácil de adoptar que una arquitectura distribuida de muy bajo acoplamiento desde el minuto uno.
La hiperconvergencia no es tan flexible como otras arquitecturas distribuidas puras, pero proporciona un buen puente entre el mundo clásico y el escalado horizontal a gran escala. Además, encaja muy bien con estrategias comerciales de “pago según creces”, ya que cada nuevo nodo tiene un coste relativamente predecible.
Escalado en bases de datos y capas de datos
Las bases de datos son un terreno especialmente sensible al tema del escalado, ya que suelen convertirse en cuello de botella antes que la capa de aplicación.
En bases de datos relacionales tradicionales, el escalado vertical sigue siendo muy frecuente: ampliar la instancia de Amazon RDS, Google Cloud SQL o el servidor físico para ganar CPU y memoria y así mejorar tiempos de consulta y throughput de transacciones.
Para ir más allá, entra en juego el escalado horizontal mediante estrategias como el sharding (particionar los datos entre varios nodos) o el uso de réplicas de lectura para aliviar la carga del nodo maestro. Sistemas como MongoDB, Cassandra o muchas bases de datos NoSQL están diseñados desde el principio para este tipo de distribución.
De nuevo, el escalado lógico es clave: elegir la clave de partición adecuada, decidir qué datos son críticos y qué consistencia necesitamos, y combinar cachés en memoria (Redis, Memcached) con almacenamiento persistente NAND para equilibrar rendimiento y durabilidad.
Kubernetes, autoscalado y orquestación
En el mundillo de los contenedores, Kubernetes se ha convertido en el estándar de facto para orquestar el escalado horizontal y lógico. Define abstracciones como pods, deployments y services que facilitan replicar y distribuir workloads.
Dos componentes relacionados directamente con el escalado son el Horizontal Pod Autoscaler (HPA), que añade o quita réplicas de pods en función de métricas (CPU, memoria u otras personalizadas), y el Cluster Autoscaler, que ajusta automáticamente el número de nodos del clúster cuando la capacidad actual no es suficiente.
Diseñar servicios stateless, usar volúmenes persistentes adecuados sobre almacenamiento NAND (a menudo SSD 3D en la nube) y apoyarse en health checks y probes de Kubernetes es fundamental para aprovechar todo el potencial del escalado horizontal automático.
Buenas prácticas para escalar vertical y horizontalmente
Para sacarle partido al escalado vertical conviene monitorizar constantemente CPU, RAM, disco y red con herramientas como CloudWatch, Prometheus o similares. Solo así sabrás cuándo te estás acercando al límite físico del servidor.
También es importante planificar bien los periodos de mantenimiento: upgrades de hardware, migraciones a instancias mayores o cambios en el tipo de almacenamiento suelen implicar al menos una ventana controlada de intervención.
En el ámbito del escalado horizontal, la regla de oro es diseñar servicios lo más stateless posible, delegando el estado en almacenes comunes. Esto facilita mover peticiones entre nodos sin romper sesiones ni datos.
Imprescindible también implementar health checks para que los balanceadores de carga y orquestadores puedan detectar nodos caídos o degradados y apartarlos automáticamente del flujo de tráfico, reduciendo el impacto en los usuarios.
Finalmente, apoyarse en herramientas de orquestación como Kubernetes, Nomad u otras plataformas gestionadas simplifica enormemente la tarea de gestionar decenas o cientos de instancias y servicios distribuídos, automatizando despliegues, actualizaciones y escalado.
Si se combina un buen diseño lógico con decisiones sensatas de cuándo usar escalado vertical, cuándo horizontal y cómo aprovechar el hardware NAND subyacente, se pueden construir sistemas que crecen de forma ordenada, con costes razonables y sin sustos cada vez que sube el tráfico.