
- RDMA permite transferencias de memoria a memoria entre servidores con latencia muy baja y casi sin uso de CPU gracias al acceso directo y la tecnología de copia cero.
- Las principales variantes son InfiniBand, RoCE e iWARP, que ofrecen distintos equilibrios entre rendimiento, coste y complejidad de red.
- RDMA se usa de forma creciente en HPC, IA, almacenamiento en red (NAS/SAN) y centros de datos virtualizados, donde desbloquea cuellos de botella de red tradicionales.
- La adopción de RDMA requiere hardware y configuración específicos, pero los beneficios en escalabilidad y eficiencia lo convierten en un componente clave de la infraestructura moderna.

Cuando empiezas a pelearte con el rendimiento de redes, bases de datos distribuidas o sistemas HPC, aparece siempre el mismo enemigo: la latencia y el consumo de CPU al mover datos entre máquinas. Ahí es donde entra RDMA (Remote Direct Memory Access), una tecnología que cambia por completo la forma tradicional de enviar información a través de la red.
Dicho en corto, RDMA permite que un servidor lea o escriba directamente en la memoria de otro servidor remoto sin que la CPU ni el sistema operativo de ese servidor tengan que procesar cada paquete. Eso se traduce en menos copias de datos, menos cambios de contexto, menos interrupciones… y un buen mordisco a la latencia de red, justo lo que necesitan centros de datos modernos, IA, big data o sistemas de trading.
Qué es RDMA (Remote Direct Memory Access)

RDMA, siglas de Remote Direct Memory Access, es una tecnología de interconexión que permite que los datos se transfieran directamente entre las memorias de dos sistemas a través de la red, sin pasar por la pila TCP/IP tradicional ni requerir la intervención continua de la CPU de los equipos implicados. La tarjeta de red especial que soporta RDMA (a menudo llamada RNIC) se encarga de mover los datos de forma autónoma.
Con RDMA, el adaptador de red puede leer o escribir bloques de memoria remota usando direcciones virtuales y claves de acceso previamente negociadas entre los dos extremos. La CPU del sistema remoto no tiene que procesar el flujo de datos paquete a paquete, lo cual reduce de manera muy significativa la sobrecarga de procesado, la latencia de mensaje y el uso de ciclos de CPU.
Esta tecnología nació y se popularizó primero en entornos de computación de alto rendimiento (HPC), donde cada microsegundo importa. Con el tiempo se ha ido extendiendo a centros de datos empresariales, nubes públicas y privadas, almacenamiento de alto rendimiento (NAS y SAN modernas) e infraestructuras para IA, gracias a variantes de RDMA que funcionan sobre Ethernet y TCP/IP.
Las implementaciones más habituales de RDMA que podemos encontrar hoy en día son InfiniBand, RoCE (RDMA over Converged Ethernet) e iWARP. Cada una tiene sus particularidades de rendimiento, coste y complejidad de despliegue, pero todas comparten la misma idea de acceso directo a memoria remota sin copias innecesarias.
Relación entre DMA tradicional y RDMA
Para entender bien RDMA conviene repasar primero qué es el DMA clásico (Direct Memory Access). En un sistema tradicional, cuando un dispositivo de E/S quiere transferir muchos datos (por ejemplo, una controladora de disco o una NIC), se apoya en un controlador DMA (DMAC). Este controlador toma el control del bus del sistema durante la transferencia, copiando datos directamente entre memoria y dispositivo sin que la CPU tenga que mover cada palabra.
En modo DMA, la CPU inicializa unos registros en el DMAC (dirección de memoria de origen o destino y contador de palabras a transferir) y se desentiende. El DMAC realiza ciclos de lectura/escritura en memoria, va incrementando la dirección (AR) y decrementando el contador (WC) tras cada palabra transferida. Cuando WC llega a 0, el controlador envía una interrupción a la CPU para notificar que ha terminado.
Este enfoque reduce el trabajo de la CPU, pero introduce problemas como los de coherencia de caché. Si la CPU tiene datos en caché que no han sido escritos todavía en memoria principal, un dispositivo usando DMA podría leer valores obsoletos. Y al revés: si el dispositivo escribe en memoria y la caché no se invalida, la CPU podría seguir viendo datos antiguos. Para evitar esto, los sistemas pueden ser de caché coherente (hardware se encarga de invalidar o volcar caché) o no coherente (el sistema operativo fuerza vaciados/invalidaciones antes y después de usar DMA).
Además, el DMA clásico puede trabajar en modo ráfaga (toma el bus hasta finalizar toda la transferencia, ideal cuando hay caché y la CPU puede seguir trabajando) o en modo robo de ciclo (cede el bus tras cada palabra transferida, útil en sistemas sin caché para que la CPU no se quede parada demasiado tiempo).
RDMA da un paso más allá: extiende esta idea de acceso directo a memoria a través de la red. En lugar de que un dispositivo local acceda a la RAM de su propio host, una NIC RDMA es capaz de leer/escribir directamente en la memoria de otra máquina remota usando la red como bus de transporte, reduciendo de forma drástica las copias y la intervención de la CPU en ambos lados.
Cómo funciona RDMA frente a una NIC tradicional
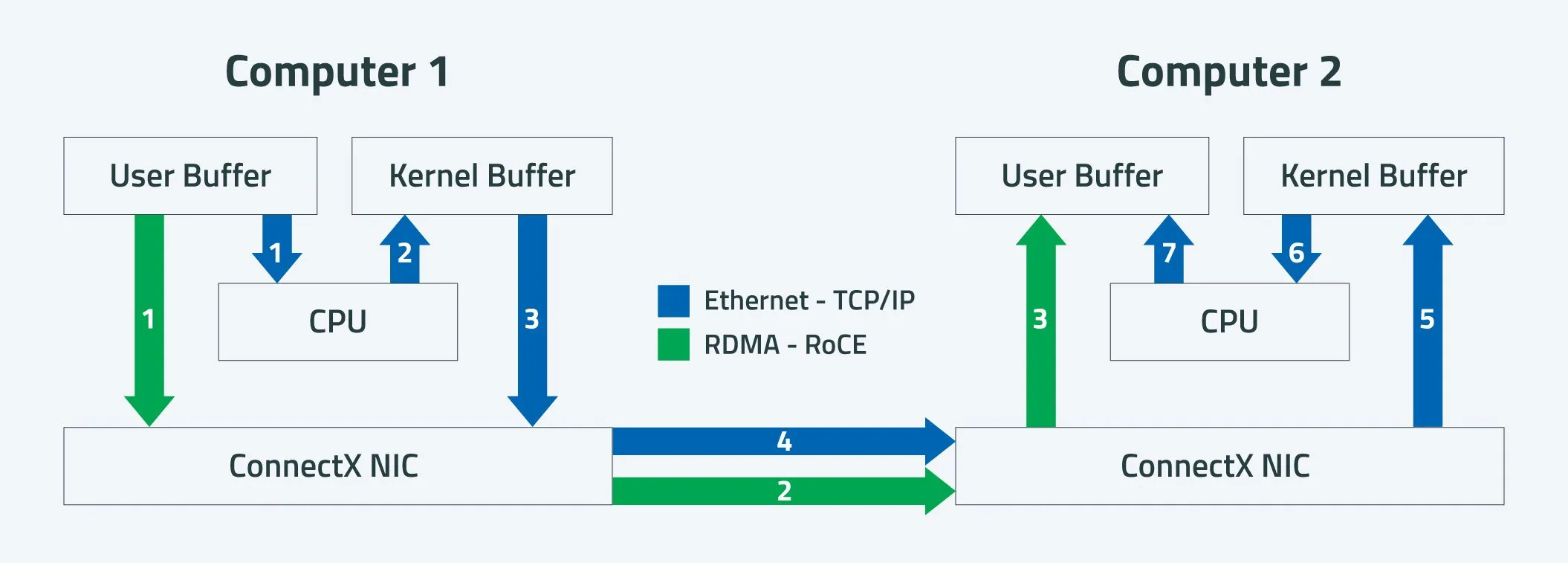
En una tarjeta de red convencional que utiliza TCP/IP, el recorrido de los datos es bastante largo. El proceso típico en el emisor es copiar los datos desde el buffer de la aplicación en espacio de usuario al buffer de socket en el kernel, añadir las cabeceras de los protocolos (TCP, IP, Ethernet), copiar los datos al buffer de la NIC y, finalmente, enviarlos por la red. En el receptor, los paquetes se reciben en el buffer de la NIC, pasan al buffer de kernel, se procesan las cabeceras, se asignan a la conexión TCP correcta y solo entonces se copian al buffer de la aplicación en el espacio de usuario.
En todo este proceso hay varias copias de memoria y numerosos cambios de contexto entre modo kernel y modo usuario. Cada interrupción recibida, cada paquete procesado y cada movimiento de datos consume ciclos de CPU y ancho de banda interno de memoria, lo que se traduce en latencia extra y en una menor eficiencia global.
Con RDMA el enfoque es muy distinto. Cuando una aplicación quiere leer o escribir datos en un sistema remoto utilizando RDMA, registra primero uno o varios buffers de memoria, obteniendo una clave de memoria (Stag u otra representación equivalente) y una dirección virtual que la NIC puede entender. A partir de ahí, las operaciones RDMA se lanzan desde el espacio de usuario directamente a la RNIC, sin necesidad de pasar por la memoria del kernel para copiar los datos.
La NIC local accede directamente al contenido del buffer de la aplicación, encapsula la información RDMA junto con la dirección virtual remota y la clave de memoria, y la envía por la red hacia la NIC remota. La RNIC de destino verifica la clave, localiza el buffer remoto y escribe o lee los datos directamente en la memoria de la aplicación remota, sin involucrar a la CPU remoto más allá de la inicialización y la notificación de finalización, que puede gestionarse mediante sondeo en espacio de usuario o mediante eventos gestionados por el kernel.
Gracias a esto, RDMA consigue dos pilares clave: cero copias (zero-copy) entre memoria de aplicación y NIC, y omisión del kernel (kernel bypass), evitando que la pila TCP/IP del sistema operativo esté en la ruta caliente de datos. El resultado es una reducción drástica de latencia, menos consumo de CPU y un aprovechamiento mucho mejor del ancho de banda disponible.
Tecnología de copia cero y bypass de kernel en RDMA
La llamada tecnología de copia cero en redes hace referencia justo a esto: a que la NIC pueda leer y escribir directamente en la memoria de la aplicación, sin pasar por buffers intermedios en el kernel. En la práctica, esto implica que los buffers de aplicación se marcan y se registran de forma especial para que puedan ser usados por la RNIC respetando el modelo de protección de memoria del sistema.
En lugar de que la CPU tenga que copiar datos entre memoria de usuario y memoria del kernel para cada operación de envío o recepción, la solicitud RDMA se emite directamente desde el espacio de usuario hacia la NIC, que ya sabe qué zonas de memoria puede tocar gracias al registro previo. Así, los cambios de contexto entre usuario y kernel se reducen, lo que contribuye a minimizar aún más la latencia.
En el receptor, la RNIC deposita los datos directamente en el buffer de la aplicación remota que se ha declarado para ello, sin un paso intermedio por el típico buffer de socket. Esto no solo elimina copias, sino que reduce muchísimo el número de interrupciones que la CPU debe atender, ya que el hardware de red realiza internamente gran parte del trabajo de procesado de la transferencia.
Esta filosofía de descarga de trabajo hacia el hardware también se ve en tecnologías como TOE (TCP Offload Engine), donde parte o todo el procesamiento de la pila TCP/IP se mueve a la NIC. En el caso de TOE, la NIC se encarga de encapsular y gestionar las cabeceras de los protocolos, y puede entregar los datos directamente al espacio de usuario, reduciendo el número de interrupciones y copias. RDMA va un paso más lejos, integrando directamente la semántica de acceso remoto a memoria sin tener que usar la interfaz de sockets tradicional.
Familia de protocolos RDMA e iWARP
Para que RDMA funcione sobre redes IP estándar se definió una familia de protocolos conocida como iWARP. Esta familia se compone de tres capas principales: el propio protocolo RDMA, el protocolo DDP (Direct Data Placement) y el protocolo MPA (Marker PDU Aligned).
La función de DDP es encapsular los mensajes RDMA en unidades de datos (paquetes DDP) que pueden colocarse directamente en los buffers de destino sin necesidad de que la CPU procese cada segmento. Estos paquetes se pasan después a la capa MPA, que añade identificadores, longitudes y comprobaciones CRC para formar los segmentos MPA preparados para circular sobre TCP.
La capa IP se encarga finalmente de añadir la información de enrutamiento necesaria para transportar los segmentos MPA a través de Internet o de una red IP privada. De este modo, iWARP hace posible que la semántica de RDMA se implemente sobre TCP/IP estándar, lo que permite aprovechar la infraestructura Ethernet ya desplegada, aunque a costa de una cierta penalización frente a soluciones más ligeras (debido al propio overhead de TCP).
Operaciones de control y tipos de mensajes RDMA
El protocolo RDMA define varias operaciones de control sobre los buffers remotos, cada una con su semántica específica. Todas ellas, salvo la lectura de memoria remota, generan un único mensaje RDMA asociado a la operación. Estas primitivas permiten una gran flexibilidad en la forma en que las aplicaciones gestionan el acceso a los buffers remotos.
Las operaciones principales son:
- Enviar (Send): Envía datos desde la aplicación emisora a un buffer en el lado receptor que no ha sido declarado explícitamente por la aplicación remota. Utiliza el modelo de buffer sin etiquetar de DDP, de modo que el mensaje se coloca en una cola de recepción metaetiquetada en el host de destino.
- Enviar con invalidación: Además de transferir los datos, invalida el acceso del emisor a un determinado buffer remoto una vez completada la operación. La aplicación receptora recibe la notificación de que los datos han llegado y, tras procesarlos, debe volver a declarar el buffer si quiere que el emisor pueda seguir utilizándolo.
- Enviar con evento solicitado (Send with SE): Igual que la operación de envío básica, pero solicita explícitamente que se genere un evento cuando el mensaje se ha procesado, permitiendo sincronización fina en el lado receptor.
- Enviar con evento solicitado e invalidación: Combina las características de las dos anteriores, de manera que se envían datos, se solicita un evento y se invalidan permisos sobre el buffer asociado al Stag indicado.
- Escritura RDMA (Remote Write): Permite escribir datos directamente en un buffer remoto que ya ha sido declarado y etiquetado por la aplicación receptora. El emisor debe conocer la dirección, tamaño y clave (Stag) del buffer remoto. Esta operación utiliza el modelo de buffer etiquetado de DDP.
- Lectura RDMA (Remote Read): Transfiere datos desde un buffer remoto etiquetado hacia un buffer local también etiquetado. La aplicación fuente debe haber declarado previamente el buffer remoto y autorizado las lecturas directas, proporcionando al lado lector la información de localización, tamaño y Stag.
- Terminar (Terminate): Envía un mensaje de error para abortar la operación de acceso directo a datos en curso, usando el modelo de buffer metaetiquetado de DDP para colocar el mensaje de terminación en el buffer adecuado del otro extremo.
Ventajas y desventajas de RDMA frente a otras tecnologías
Una de las grandes bazas de RDMA es su velocidad de transferencia, que en muchas implementaciones supera a tecnologías consolidadas como iSCSI, Fibre Channel (FC) o FCoE. Soluciones basadas en InfiniBand o Ethernet con RDMA pueden alcanzar anchos de banda de 10 a 100 Gb/s (e incluso más en generaciones recientes), lo que las hace ideales para aplicaciones que requieren mucha potencia de cómputo y movimiento de datos intensivo.
Entornos como las bases de datos distribuidas, el análisis de big data o los grandes centros de datos que sirven servicios en la nube se benefician especialmente: la menor latencia y la reducción de uso de CPU permiten escalar a más nodos sin disparar los costes de hardware y energía. Además, en ámbitos como IA y HPC, donde hay que intercambiar parámetros y modelos de forma continua entre nodos, RDMA ayuda a evitar que la red sea el cuello de botella.
Sin embargo, no todo son ventajas. Para implantar RDMA en una organización suele ser necesario invertir en hardware específico: tarjetas de red con soporte RDMA (InfiniBand, RoCE o iWARP), y en algunos casos switches preparados para tecnologías como PFC y ECN en Ethernet sin pérdidas. Esto hace que el coste inicial pueda ser sensiblemente superior a soluciones basadas solamente en FC, FCoE o IP estándar.
Otro punto a tener en cuenta es que el beneficio de RDMA solo se materializa cuando todos los sistemas implicados en la comunicación soportan la tecnología y están correctamente configurados. Si solo una parte de la infraestructura utiliza RDMA, el resto de los sistemas seguirán limitados por la pila TCP/IP tradicional, lo que reduce el impacto real de la inversión.
A pesar de todo, gracias a la adopción de RDMA sobre Ethernet (RoCE e iWARP) y a la integración de esta tecnología en sistemas operativos como Linux, Windows Server o Solaris, su despliegue es cada vez más accesible y se considera ya un componente clave en muchas arquitecturas modernas de centro de datos.
Variantes y redes RDMA: InfiniBand, RoCE e iWARP
Actualmente, las tres principales tecnologías de red que implementan RDMA son InfiniBand, RoCE e iWARP, cada una con su filosofía y ámbito de aplicación. Aunque comparten el objetivo de ofrecer acceso remoto a memoria con baja latencia y alto rendimiento, difieren en el tipo de infraestructura que requieren y en los mecanismos que usan para garantizar fiabilidad.
InfiniBand fue diseñada específicamente como una red para RDMA de alto rendimiento. Utiliza un modo de reenvío de paquetes tipo cut-through, minimizando la latencia en cada salto. Su control de flujo basado en créditos garantiza que no se pierdan paquetes, lo que simplifica la lógica de retransmisión. Eso sí, necesita HCAs (Host Channel Adapters) y switches InfiniBand dedicados, con un coste de hardware más elevado que una red Ethernet estándar, aunque a cambio proporciona latencias extremadamente bajas (del orden de 100 ns) y un rendimiento sobresaliente en entornos HPC.
RoCE (RDMA over Converged Ethernet) traslada el protocolo de transporte de InfiniBand a una red Ethernet. RoCEv1 opera en la capa de enlace (L2) y solo se puede usar dentro del mismo dominio de broadcast, mientras que RoCEv2 se encapsula sobre UDP/IP y puede funcionar en redes IP de capa 3, permitiendo enrutamiento. Para garantizar una comunicación fiable, RoCE aprovecha mecanismos de Ethernet sin pérdidas como PFC (Priority-based Flow Control) y ECN (Explicit Congestion Notification), lo que exige una configuración cuidadosa de los switches. La ventaja es que permite usar gran parte de la infraestructura Ethernet existente, con NICs RDMA específicas pero sin necesidad de switches propietarios, logrando una relación precio/rendimiento muy atractiva para centros de datos.
iWARP, por su parte, implementa RDMA sobre la pila TCP/IP estándar. Se apoya en TCP para el control de flujo y la gestión de la congestión, lo que simplifica la red subyacente: no requiere switches especiales ni configuraciones de DCB (Data Center Bridging). Basta con que las tarjetas de red de los servidores soporten iWARP para poder utilizar RDMA sobre Ethernet convencional. El inconveniente es que el uso de TCP introduce algo más de overhead y puede consumir más recursos de CPU en grandes despliegues, por lo que su rendimiento suele ser ligeramente inferior al de RoCE en escenarios muy exigentes.
En la práctica, InfiniBand se mantiene fuerte en supercomputación y clústeres HPC muy especializados, mientras que RoCE se ha popularizado en centros de datos comerciales por su equilibrio entre prestaciones y coste. iWARP queda como alternativa válida en entornos donde se quiere evitar la complejidad de redes Ethernet sin pérdidas, asumiendo una pequeña penalización de rendimiento.