
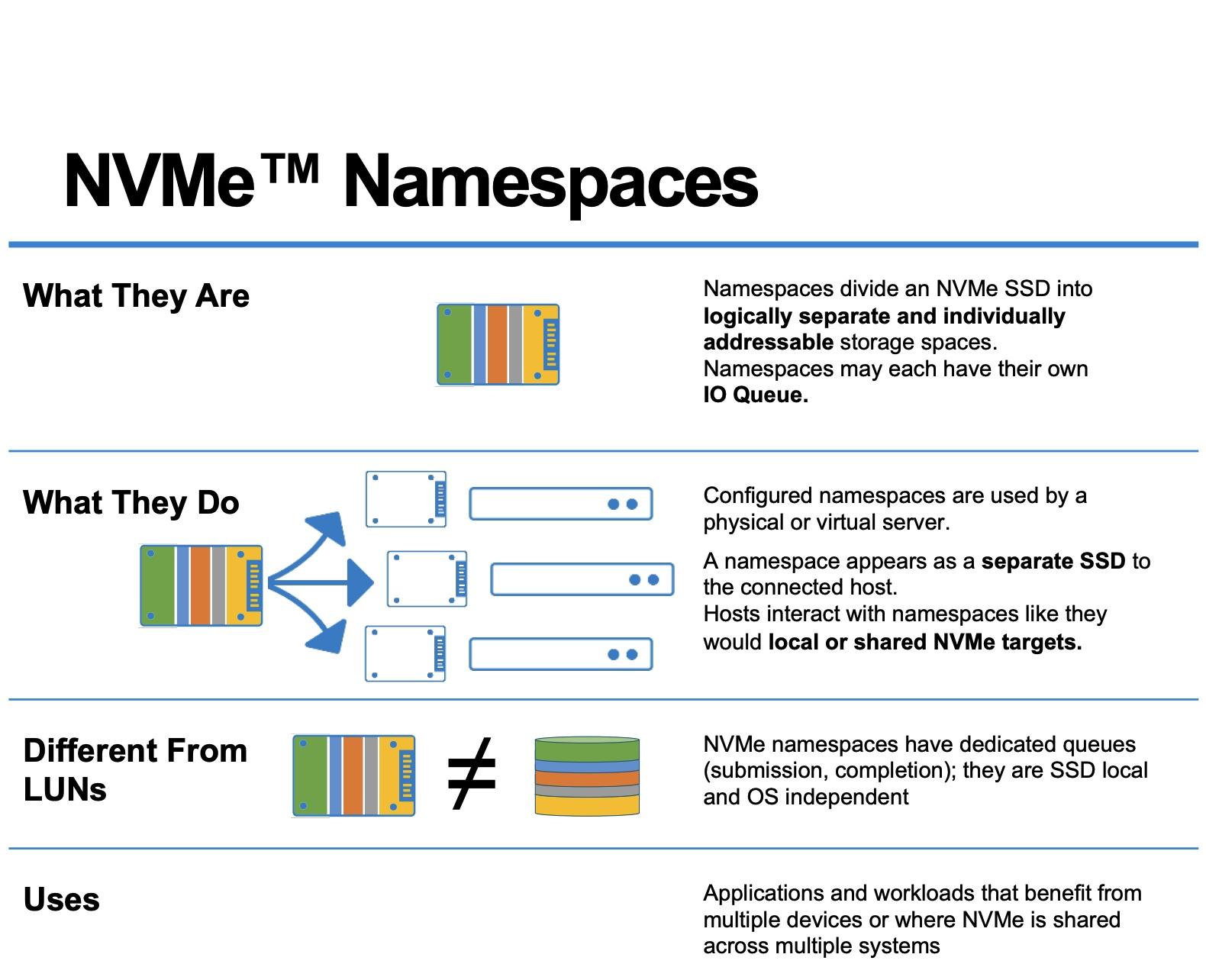
- Un namespace en NVMe es un conjunto de bloques lógicos (LBA) que el host ve como un dispositivo de bloque independiente, con tamaño, capacidad y utilización propios.
- Los namespaces permiten separar lógicamente capacidad, seguridad, rendimiento y sobreaprovisionamiento dentro de un mismo SSD, e incluso aplicar cifrado y protección de escritura por namespace.
- En Linux y en contenedores, los namespaces aíslan recursos como red, PID, montajes o usuarios, y se usan en herramientas como Flatpak, Docker o Podman mediante utilidades como unshare y nsenter.
- En Kubernetes, los namespaces segmentan lógicamente el clúster para organizar recursos, evitar conflictos de nombres y aplicar políticas de acceso y cuotas por equipo o proyecto.
Si te estás metiendo de lleno en el mundo del almacenamiento moderno con SSD y NVMe en Linux, es normal que al principio todo suene a sopa de siglas: namespaces, LBA, ZNS, LVM, contenedores, Kubernetes… En realidad, muchas de estas piezas encajan entre sí, pero pertenecen a capas distintas: unas son de hardware, otras del sistema operativo y otras del plano de orquestación o virtualización.
En este artículo vamos a centrarnos en qué son los namespaces de SSD (especialmente en NVMe), para qué sirven, cómo se gestionan y cómo se relacionan con otros tipos de namespaces que quizá ya conozcas, como los de Linux o los de Kubernetes. Iremos hilando conceptos con calma, usando ejemplos prácticos en Linux, y también veremos cómo encajan tecnologías como Zoned Namespaces (ZNS), Flatpak, contenedores o Kubernetes dentro de este rompecabezas.
Qué es un namespace en un SSD NVMe
En la terminología de NVMe, un namespace es un conjunto de direcciones de bloque lógicas (LBA) que el host puede ver y utilizar como si fuera un dispositivo de bloque independiente. No es un trozo de chips físicamente separado, sino una segmentación lógica del espacio de direcciones del SSD.
El SSD organiza los datos en bloques lógicos numerados (LBA 0, 1, 2, …). Un namespace agrupa un subconjunto de esos bloques, de forma que el sistema operativo lo ve como si fuera un disco distinto. Cada namespace tiene un identificador, llamado NSID (Namespace ID), que el controlador NVMe usa para referirse a él.
Desde el punto de vista de Linux, cada namespace se expone como un dispositivo de bloque independiente bajo /dev. Por ejemplo, en un SSD NVMe podrás ver algo como /dev/nvme0n1, donde nvme0 identifica al controlador y n1 indica que se trata del namespace 1 asociado a ese controlador.
Esto implica que un solo SSD NVMe puede dividirse en múltiples namespaces lógicos, todos compartiendo internamente los mismos chips de memoria flash, pero presentándose al sistema como discos separados que puedes tratar de forma distinta: sistemas de archivos diferentes, políticas de seguridad distintas, tamaños diferenciados, etc.
Cómo se ven los namespaces NVMe en Linux
En un sistema Linux típico con NVMe, es habitual encontrar dispositivos como /dev/nvme0, /dev/nvme1… que representan a los controladores, y a la vez dispositivos como /dev/nvme0n1, /dev/nvme0n2… que representan los namespaces asociados a cada controlador.
Cuando a un namespace le creas una tabla de particiones tradicional (por ejemplo con GPT), Linux muestra las particiones como /dev/nvme0n1p1, /dev/nvme0n1p2, etc.. En esta nomenclatura, la “n” alude al namespace y la “p” a la partición, de forma que /dev/nvme0n0p1 significa: controlador 0, namespace 0, partición 1.
Una vez que el namespace está visible como dispositivo de bloque, puedes tratarlo como cualquier otro disco: crear particiones, usar LVM para agruparlo con otros dispositivos o namespaces, construir volúmenes lógicos que abarquen varios discos, y encima de eso, montar sistemas de archivos como ext4, XFS, btrfs, etc.
Si quisieras usar un namespace directamente como bloque sin sistema de archivos (por ejemplo, para dárselo en bruto a una base de datos o a una capa de software definida por software), necesitarías que ese namespace no tenga una tabla de particiones tradicional por encima, o bien gestionar el mapeo directamente con la aplicación o la capa intermedia que lo vaya a usar.
Tamaño, capacidad y utilización de un namespace NVMe
El estándar NVMe define una estructura de datos llamada Identify Namespace, que es la que describe todo lo relacionado con un namespace: tamaño, capacidad, utilización, formatos de LBA, capacidades de protección, etc. Esta información se puede consultar con herramientas como nvme-cli para comprobar la salud de tu SSD en Linux.
Dentro de esa estructura destacan tres campos clave, que conviene tener muy claros para entender cómo se gestiona el espacio:
- Namespace Size (NSZE): número total de bloques lógicos que componen el namespace; es el rango de direcciones disponible (de LBA 0 a LBA n-1).
- Namespace Capacity (NCAP): máximo número de bloques que se pueden asignar en un momento dado; normalmente se usa para reservar parte del espacio como área no accesible al host.
- Namespace Utilization (NUSE): cantidad de bloques lógicos actualmente asignados; te permite ver cómo responde el dispositivo a las órdenes de liberación de bloques (TRIM o deallocate).
Cuando se formatea un namespace, lo habitual es que la utilización (NUSE) arranque en cero. A medida que se escriben datos, NUSE va aumentando y, cuando se emiten comandos de deallocate/TRIM, el controlador puede liberar bloques y reducir esa utilización. Esta métrica es muy útil para entender qué tal está gestionando el SSD la reutilización del espacio y para interpretar SMART del SSD.
Además, la orden Identify Namespace también informa de las características del formato de LBA soportados: tamaños óptimos de bloque, si hay soporte para información de protección de extremo a extremo, posibles formatos alternativos, etc. Esto orienta al sistema operativo y a las aplicaciones sobre cómo generar peticiones más eficientes para ese namespace concreto.
Gestión de namespaces NVMe: creación, borrado y adjunción
La especificación NVMe diferencia entre dos grandes tipos de operaciones relacionadas con namespaces: las de gestión de namespaces y las de adjuntar/detach namespaces a controladores. Esta separación es importante porque en una misma controladora NVMe puede haber varios controladores lógicos dentro de un subsistema.
Por un lado, están las operaciones de Namespace Management, que permiten crear, modificar o eliminar namespaces. Por otro, las operaciones de Namespace Attachment, con las que se adjunta o se desadjunta un namespace a uno o más controladores dentro del subsistema NVMe.
Un detalle que suele pasar desapercibido es que, cuando el host crea un namespace, ese namespace todavía no es visible como dispositivo de bloque hasta que se adjunta a un controlador. Solo después de adjuntarlo y reinicializar el dispositivo (por ejemplo, con un nvme reset) aparecerá como /dev/nvmeXnY en el sistema.
El estándar también distingue entre namespaces privados y namespaces compartidos. Un namespace privado está adjunto a un único controlador, mientras que un namespace compartido puede estar adjunto a dos o más controladores dentro del mismo subsistema. Esta idea resulta muy útil para escenarios de alta disponibilidad o para acceso desde varias rutas.
Por qué crear múltiples namespaces en un SSD
Dividir un SSD NVMe en varios namespaces tiene ventajas muy claras para distintos tipos de carga de trabajo, sobre todo en entornos de centros de datos, nubes públicas o plataformas multi‑tenant donde se comparte el mismo hardware entre muchos usuarios o aplicaciones.
Una de las motivaciones principales es la separación lógica entre clientes o servicios. Cada tenant puede tener su namespace propio con políticas de rendimiento, seguridad y capacidad adaptadas a su caso de uso, sin necesidad de comprar varios SSD físicos para lograr esa separación.
Otra razón habitual es la segmentación de la seguridad. Al contar con namespaces independientes, se pueden aplicar mecanismos de cifrado por namespace, esquemas de protección específicos o incluso configuraciones de solo lectura para ciertos entornos (por ejemplo, un namespace que contiene la imagen de arranque de un sistema operativo).
También es un recurso potente para controlar la calidad de servicio y el rendimiento. Ajustando el tamaño de cada namespace se puede forzar cierto grado de sobreaprovisionamiento interno, mejorando la latencia y la resistencia al desgaste en los namespaces que soportan más escritura intensa.
Por último, disponer de varios namespaces independientes ayuda a organizar el almacenamiento de forma más limpia: diferentes sistemas de ficheros o aplicaciones en namespaces separados te facilitan la administración, las tareas de mantenimiento, el formateo independiente y la recuperación de datos en casos de fallo de software.
Overprovisioning y ajustes de tamaño de namespaces
Los SSD siempre reservan internamente una porción de espacio que el host no ve, usada como área de sobreaprovisionamiento para tareas como garbage collection, TRIM, nivelación de desgaste, etc. La gracia es que, con namespaces, puedes afinar este comportamiento a tu gusto.
Si en un SSD de, por ejemplo, 3,84 TB defines un namespace que exponga menos capacidad al host (digamos 3,2 TB en lugar de la capacidad física bruta), estás dejando una mayor fracción de espacio como zona no provisionada visible solo para el controlador. Este aumento de sobreaprovisionamiento suele mejorar la resistencia (más ciclos de borrado disponibles), la regularidad de la latencia y el rendimiento sostenido en operaciones de escritura intensiva.
Lo bueno de los namespaces es que este planteamiento se puede aplicar por namespace. Puedes definir namespaces con más o menos sobreaprovisionamiento relativo según el tipo de carga que se vaya a ejecutar en cada uno: bases de datos transaccionales, almacenamiento de logs, volúmenes de solo lectura, etc.
A la hora de crear un namespace nuevo, el host debería tener en cuenta parámetros como la granularidad de tamaño y capacidad de namespace. La objetivo es reducir al mínimo el espacio que queda sin direccionar debido a alineaciones internas entre tamaño de bloque formateado, granularidad de asignación, etc. Cuando Namespace Size = Namespace Capacity y se respetan las granularidades de tamaño y capacidad, se considera que el namespace está totalmente provisionado desde el punto de vista de la dirección lógica.
Herramientas como nvme-cli permiten llevar a cabo los pasos típicos: desadjuntar namespaces existentes, eliminarlos, volver a crearlos con el tamaño deseado, adjuntarlos de nuevo a los controladores pertinentes, reiniciar el dispositivo y verificarlo con nvme list. Todo ello se puede automatizar para gestionar flotas de SSD en entornos de producción.
Seguridad y cifrado por namespace
Muchos SSD modernos implementan estándares de seguridad como OPAL, que permiten cifrar rangos de LBA con claves específicas. El uso combinado de OPAL con namespaces ofrece un abanico muy interesante de estrategias de protección de datos.
Cuando solo hay un namespace disponible, es posible definir varios rangos de bloqueo para aplicar cifrado selectivo dentro del mismo espacio lógico, de modo que ciertas áreas del disco estén protegidas de forma diferente al resto. Esto puede ser útil si solo un subconjunto de los datos es especialmente sensible.
Sin embargo, si configuras múltiples namespaces, cada uno puede asignarse a un tenant o aplicación distinta, lo que simplifica enormemente el modelo de seguridad. A cada namespace se le podría aplicar una política de cifrado y de control de acceso propia, evitando que un usuario pueda ver o manipular el contenido de namespaces ajenos, aunque compartan físicamente el mismo SSD.
OPAL y tecnologías similares proporcionan barreras contra accesos no autorizados desde fuera del sistema, pero también ayudan a evitar que distintos usuarios que comparten una misma unidad puedan interferirse o espiar datos pertenecientes a otros namespaces, incluso si logran comprometer parte del software de la máquina.
Además del cifrado, muchos controladores NVMe ofrecen modos de protección de escritura por namespace. Se puede marcar un namespace como solo lectura hasta el siguiente ciclo de energía, solo lectura hasta que se desactive la protección, o incluso solo lectura permanente durante toda la vida útil de la unidad, algo muy valorado en sistemas embebidos o de alta seguridad.
Namespaces de solo lectura y casos de uso en sistemas móviles y de escritorio
La capacidad de declarar un namespace como de solo lectura resulta especialmente práctica para escenarios en los que se quiere garantizar al máximo la integridad de cierto software o datos críticos, como el sistema operativo de un dispositivo móvil, un entorno de arranque seguro o una imagen base.
Un controlador NVMe puede ofrecer distintos niveles de protección de escritura por namespace, desde restricciones temporales hasta un bloqueo irreversible. Mientras un namespace está en modo solo lectura, no se puede modificar, formatear, sanear ni eliminar, lo que añade una capa adicional de defensa contra borrados accidentales o ataques maliciosos.
En un PC o portátil, un diseño bastante lógico sería colocar el sistema operativo en un namespace protegido contra escritura, de forma que quede blindado, y usar otro namespace aparte como área de lectura y escritura para datos de usuario y aplicaciones. Así, incluso si un malware compromete la parte de lectura y escritura, el núcleo del sistema resulta mucho más difícil de corromper.
En el ámbito móvil o embebido, esta separación por namespaces permite crear entornos de arranque muy controlados, donde el firmware y el sistema básico se alojan en un namespace rígidamente protegido, mientras que el resto de la memoria flash puede reutilizarse libremente sin comprometer esa base.
Todo esto ilustra cómo los namespaces, más allá de particionar lógicamente el almacenamiento, ofrecen un mecanismo muy flexible para combinar seguridad, integridad y flexibilidad de uso dentro de un mismo dispositivo físico.
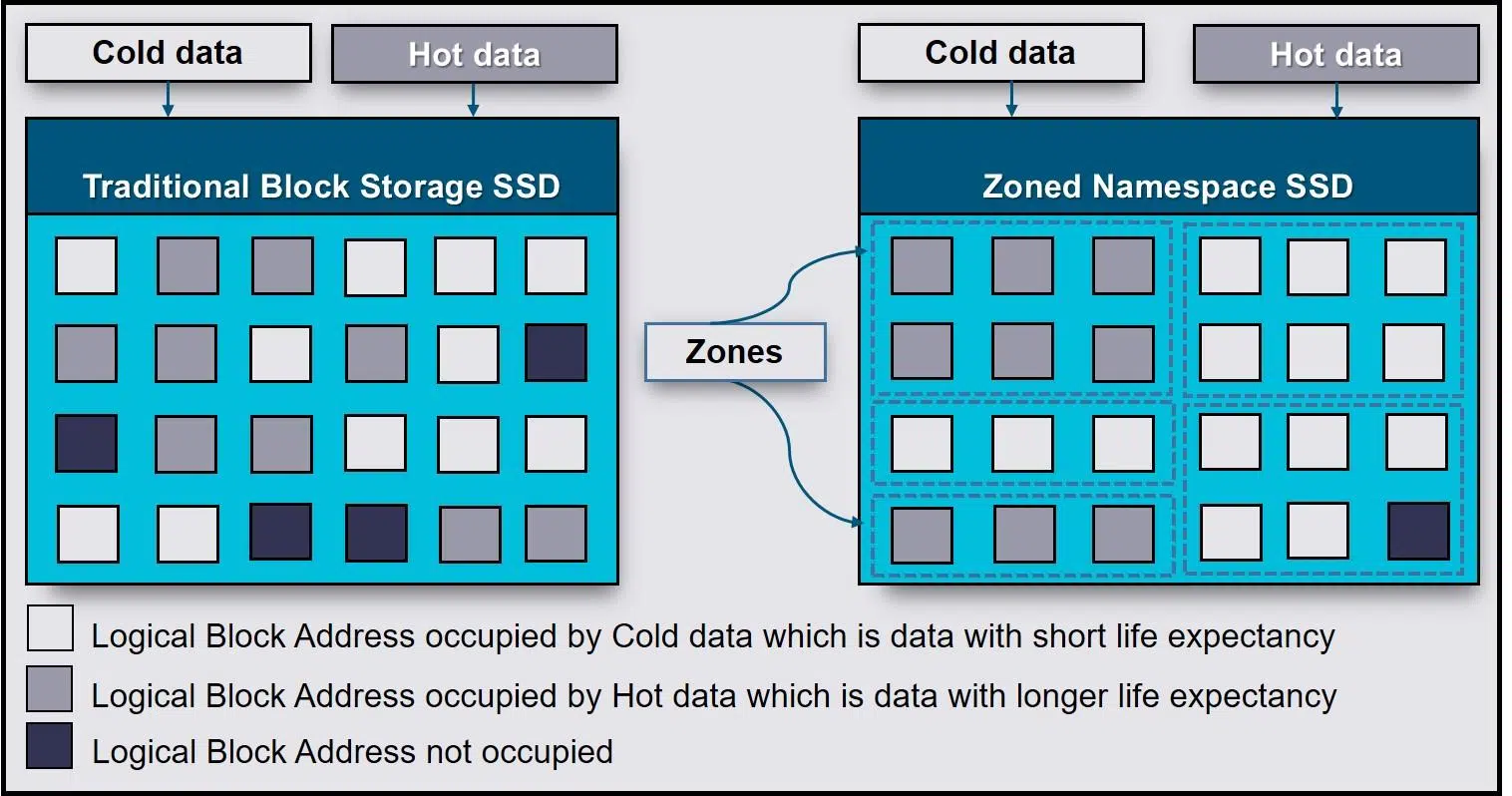
Namespaces NVMe y Zoned Namespaces (ZNS)
Dentro de la evolución del estándar NVMe, una de las extensiones más relevantes es la de los Zoned Namespaces (ZNS). En este modelo, los namespaces no solo definen un espacio lógico de bloques, sino que imponen una organización por zonas con reglas específicas de escritura y reutilización.
Los SSD ZNS están pensados para arquitecturas altamente escalables como servicios en la nube, mega plataformas digitales o infraestructuras de centro de datos con cargas de trabajo muy intensivas en datos. Su objetivo principal es reducir el coste de la sobreaprovisionamiento tradicional, disminuir la amplificación de escritura y recortar la latencia de cola larga.
En un namespace de tipo ZNS, el host escribe los datos siguiendo una estrategia de append secuencial por zonas. Esto permite que el controlador NVMe simplifique parte de la gestión interna (como el garbage collection), porque tiene información más precisa sobre cómo se usan las zonas y cuándo pueden reciclarse los bloques, disminuyendo así la cantidad de movimientos internos de datos.
Este enfoque resulta muy atractivo para servicios como almacenamiento de objetos, grandes bases de datos distribuidas o sistemas de logging masivo, donde se puede adaptar la aplicación para aprovechar la semántica de zonas. A cambio, el software debe ser consciente de que el namespace ZNS no se comporta como un bloque aleatorio tradicional, y hay que respetar las reglas de las zonas para no penalizar el rendimiento.
En resumen, los ZNS SSD se apoyan en el mismo concepto de namespace NVMe, pero añaden una capa de estructura interna adicional que facilita escalar capacidad y rendimiento en infraestructuras modernas sin disparar los costes de sobreaprovisionamiento y sin sufrir tanta amplificación de escritura.
Otros tipos de namespaces: Linux, contenedores y Flatpak
Hasta ahora hemos hablado de namespaces desde la óptica del almacenamiento NVMe, pero en Linux el término “namespace” también tiene otro significado muy importante relacionado con el aislamiento de recursos del sistema. Aunque son conceptos distintos, ambos comparten la idea base de crear “mundos separados” dentro de un mismo recurso físico.
En el kernel de Linux, un namespace es un mecanismo para aislar recursos globales como la pila de red, los identificadores de proceso, los puntos de montaje, los usuarios, los grupos, los relojes del sistema, etc. Cada proceso pertenece a uno o varios namespaces, y dentro de ellos ve una visión “local” del recurso, como si fuera el único que lo usara.
Algunos de los tipos de namespaces más habituales en Linux son:
- cgroup: controla límites de recursos (CPU, memoria, I/O, etc.).
- ipc: aísla mecanismos de comunicación entre procesos (colas de mensajes, semáforos, memoria compartida).
- mount (mnt): define un conjunto aislado de puntos de montaje.
- net: proporciona su propia pila de red, interfaces, tablas de rutas, reglas de firewall, etc.
- pid: separa el espacio de identificadores de proceso, de modo que un proceso puede ver un PID 1 diferente al del host.
- user: aísla identidades de usuario y grupo (UID, GID, capacidades).
- uts: define nombres de host y dominios aislados.
- time: permite diferentes vistas del tiempo y de ciertos relojes.
Si quieres inspeccionar los namespaces a los que pertenece un proceso, puedes mirar los enlaces simbólicos en /proc/<PID>/ns/. Cada enlace representa un tipo de namespace, y procesos que comparten el mismo inode apuntan al mismo espacio de nombres para ese recurso.
Esta infraestructura de namespaces es la base técnica de tecnologías muy populares como Docker, Podman, LXC o Flatpak. Los contenedores, al final, son procesos a los que se les asignan conjuntos específicos de namespaces para que parezca que corren en un sistema aislado, aunque en realidad compartan el mismo kernel con el host.
Namespaces en Flatpak: bubblewrap y aislamiento de aplicaciones
Flatpak es un sistema de distribución de aplicaciones para Linux que apuesta por empaquetar las apps junto con sus dependencias y ejecutarlas en un entorno aislado con ayuda de distintas capacidades del kernel, entre ellas los namespaces.
La herramienta clave que usa Flatpak para crear ese “recinto” es bubblewrap (bwrap), que se encarga de montar una sandbox con diferentes namespaces de usuario, PID, red, puntos de montaje, etc. De este modo, la aplicación ve un entorno bastante controlado, con su propio sistema de ficheros aparente y recursos aislados.
Si examinas los procesos asociados a una aplicación Flatpak (por ejemplo, un editor de texto como MarkText o un cliente de música como Spotify), verás que ciertos procesos tienen namespaces específicos para mnt, pid y user, mientras que otros procesos del sistema como systemd o bash comparten los namespaces del host. Eso indica que la app está realmente corriendo en un espacio de nombres separado para esos recursos.
Para ver exactamente qué namespaces tiene un proceso de Flatpak, puedes inspeccionar los ficheros en /proc/<PID>/ns/ o usar herramientas de diagnóstico. Notarás que los namespaces de cgroup, ipc, net, uts o time pueden ser compartidos o no según la configuración de seguridad concreta del contenedor de Flatpak.
Esta manera de aislar recursos es una forma de “virtualización ligera”: en vez de crear una máquina virtual completa, se define una combinación de namespaces que hacen que la aplicación crea que tiene su propia vista del sistema, pero en realidad comparte el mismo kernel con el resto.
Jugar con namespaces de Linux: unshare y nsenter
Si quieres entender de verdad cómo funcionan los namespaces de Linux, nada mejor que experimentar con herramientas como unshare y nsenter, que permiten crear nuevos espacios de nombres o entrar en los de otro proceso.
La utilidad unshare se usa para arrancar un comando dentro de nuevos namespaces recién creados. Por ejemplo, puedes lanzar una shell con namespaces aislados de usuario y PID, de manera que dentro de esa shell el proceso ve su propio espacio de PIDs, donde él mismo es el PID 1, y además puede mapear usuarios de forma distinta (por ejemplo, ser “nobody” en ese espacio).
En muchos casos, es necesario usar la opción –fork al invocar unshare, para que se cree realmente un proceso hijo que actúe como PID 1 dentro del nuevo namespace. Si no se hace así, pueden aparecer problemas extraños como errores de montaje de /proc o mensajes de falta de memoria al intentar hacer fork, porque el proceso no tiene un contexto completo de namespace de usuario y PID.
Otra bandera interesante es –mount-proc. Si no montas un /proc adecuado dentro del nuevo namespace, comandos que dependen de /proc/<PID>/exe (como basename con readlink) pueden fallar al intentar acceder al /proc del host con PIDs que no cuadran, lo que provoca errores de acceso no permitido. Montar /proc dentro del namespace evita estos problemas y mantiene el aislamiento.
La herramienta nsenter, por su parte, permite entrar en los namespaces de un proceso ya existente. Por ejemplo, puedes localizar el PID principal de bwrap que gestiona una app Flatpak y, con nsenter, lanzar una shell dentro de sus namespaces de red, mount o PID para investigar desde dentro cómo ve el sistema esa aplicación.
Namespaces, contenedores y Kubernetes
Los mismos mecanismos de namespaces que hemos visto en Linux se aprovechan ampliamente en tecnologías de contenedores como LXC, Docker o Podman. Cada contenedor se ejecuta dentro de un conjunto de namespaces que aísla su pila de red, sus procesos, sus montajes, etc., dando la impresión de que cada contenedor vive en su propio pequeño sistema.
Sobre esa base de aislamiento a nivel de kernel se construyen capas más altas como Kubernetes, que introduce su propio concepto de namespace de Kubernetes. En este caso, el término “namespace” no se refiere a un recurso del kernel, sino a un mecanismo lógico para segmentar un clúster en varios “clústeres virtuales” dentro del plano de control de Kubernetes.
En Kubernetes, un namespace sirve para crear ámbitos de aislamiento lógico y organización dentro del mismo clúster: cada equipo, proyecto o entorno (desarrollo, preproducción, producción) puede tener su propio namespace, con sus pods, servicios y volúmenes persistentes.
Una de sus grandes ventajas es que evita conflictos de nombres. Puedes tener un servicio llamado mi-servicio en un namespace y otro con el mismo nombre en otro namespace sin que choquen, ya que cada uno pertenece a un ámbito de nombres distinto. Esto facilita la convivencia de muchas aplicaciones en un solo clúster.
Los namespaces de Kubernetes también se integran con RBAC (Role-Based Access Control) y con los mecanismos de cuotas de recursos. Así, puedes definir qué usuarios o cuentas de servicio pueden acceder a qué recursos dentro de un namespace, y a la vez limitar el consumo de CPU, memoria o almacenamiento de cada grupo de trabajo.
Todo ello convierte a los namespaces de Kubernetes en una pieza clave para implementar entornos multi‑tenant seguros y ordenados sobre un mismo clúster, a la vez que se simplifica mucho la gestión diaria de recursos y la segmentación de aplicaciones.
Visto todo el panorama, los namespaces aparecen como un concepto que atraviesa varias capas: desde el nivel más bajo del SSD NVMe, donde segmentan bloques lógicos, hasta el kernel de Linux, donde aíslan recursos del sistema, y el plano de orquestación de Kubernetes, donde organizan recursos lógicos del clúster. Entender cómo encajan estas piezas te permite diseñar infraestructuras más limpias, seguras y escalables, aprovechando al máximo el hardware moderno y las capacidades del sistema operativo sin perder de vista la realidad de tu carga de trabajo.
