
- CrystalDiskInfo lee e interpreta los datos SMART de HDD y SSD para mostrar su salud, temperatura, horas de uso y errores internos.
- La clave está en entender la tabla SMART (Current, Worst, Threshold y Raw) y vigilar atributos como sectores reasignados o errores CRC.
- El diagnóstico es muy fiable en SSD, mientras que en HDD conviene complementarlo con CHKDSK, escaneos de superficie y atención a síntomas físicos.
- Ante estados de precaución o fallo, es vital hacer copia de seguridad, revisar el sistema y, si los errores persisten, reemplazar la unidad.
CrystalDiskInfo se ha convertido en una herramienta imprescindible para cualquiera que quiera vigilar de cerca la salud de sus discos duros mecánicos (HDD) y unidades de estado sólido (SSD). No solo muestra temperatura, modelo o capacidad: su mayor valor está en que interpreta por ti los datos S.M.A.R.T. del disco, que son algo así como su “historial médico” interno.
El problema es que la interfaz puede asustar a primera vista: columnas con nombres como “Current, Worst, Threshold, Raw Value”, atributos extraños tipo “Read Error Rate” o “UltraDMA CRC Error Count”… y un montón de números que no está nada claro cómo leer. Si a eso le sumas que no se comporta igual con un SSD que con un HDD, es fácil terminar más confundido que al empezar.
Qué es exactamente CrystalDiskInfo y para qué sirve

CrystalDiskInfo es un programa gratuito para Windows pensado exclusivamente para monitorizar unidades de almacenamiento: discos duros clásicos, SSD SATA, SSD NVMe, unidades externas USB e incluso arreglos RAID de Intel y AMD si el sistema se lo permite. Su misión principal es leer los datos S.M.A.R.T. del firmware del disco y mostrarlos en un formato entendible.
SMART (Self-Monitoring, Analysis and Reporting Technology) es un estándar que incorporan los discos para registrar internamente errores, horas de funcionamiento, temperaturas, ciclos de escritura, sectores reasignados y otros muchos parámetros. CrystalDiskInfo actúa como traductor de toda esa información cruda y la convierte en un diagnóstico rápido mediante un estado de salud y datos numéricos detallados.
En SSD modernos la lectura de CrystalDiskInfo suele ser muy precisa respecto al desgaste real: los atributos SMART reflejan fielmente cuántos terabytes se han escrito (TBW), cuántos bloques se han ido degradando o cuánta vida útil estima el fabricante que queda. En discos mecánicos, en cambio, la cosa es más delicada: puede marcar “Bueno” mientras el sistema ya va lento o aparecen pequeños cuelgues causados por sectores que aún no se han declarado como dañados.
Por eso, CrystalDiskInfo es una herramienta magnífica pero no mágica. En SSD puedes fiarte bastante de su diagnóstico. En HDD conviene usarlo como referencia, pero complementando con otras pruebas (CHKDSK, escaneos de superficie, escuchar ruidos raros, etc.). Aun así, tenerlo a mano y revisarlo cada cierto tiempo es una de las mejores formas de adelantarte a un posible desastre de datos.
Cómo descargar CrystalDiskInfo y tipos de versiones
Siempre es recomendable descargar CrystalDiskInfo desde fuentes fiables, preferiblemente la página oficial de CrystalDewWorld o repositorios reconocidos. El programa es compatible con Windows XP en adelante y funciona perfectamente en Windows 10 y Windows 11, tanto en 32 como en 64 bits, e incluso con procesadores ARM mediante un ejecutable específico.
Encontrarás normalmente tres modalidades principales para Windows de escritorio:
- Versión ZIP (portátil): viene comprimida en un archivo ZIP. Basta con descomprimirlo y ejecutar el programa, sin instalación. Ideal para llevarlo en un pendrive y usarlo en cualquier PC.
- Versión INSTALLER: incluye un instalador .exe clásico. Deja accesos directos, integra opciones en el menú Inicio y se comporta como cualquier programa instalado.
- Código fuente: pensado para desarrolladores o curiosos que quieran auditar el programa o compilarlo por su cuenta.
Dentro de la versión portátil encontrarás varios ejecutables, y es importante elegir el adecuado:
- DiskInfo32.exe: para sistemas operativos Windows de 32 bits.
- DiskInfo64.exe: para la inmensa mayoría de PCs actuales con Windows de 64 bits.
- DiskInfoA64.exe: para equipos con procesador ARM (algunos portátiles y tablets específicos).
En cuanto al aspecto visual, CrystalDiskInfo ofrece varias “ediciones” que en realidad son skins: la Standard Edition (clásica), y las Shizuku y Kurei Kei Edition, que añaden fondos e ilustraciones de estilo anime japonés. A nivel de funciones, todas son idénticas; solo cambia la apariencia.
Si solo quieres comprobar la salud del disco sin complicarte, la versión portable es la más cómoda: la copias a un USB, la ejecutas en cualquier ordenador, analizas los discos y te marchas sin dejar rastro en el sistema ni tocar el registro de Windows.
Información básica que muestra CrystalDiskInfo
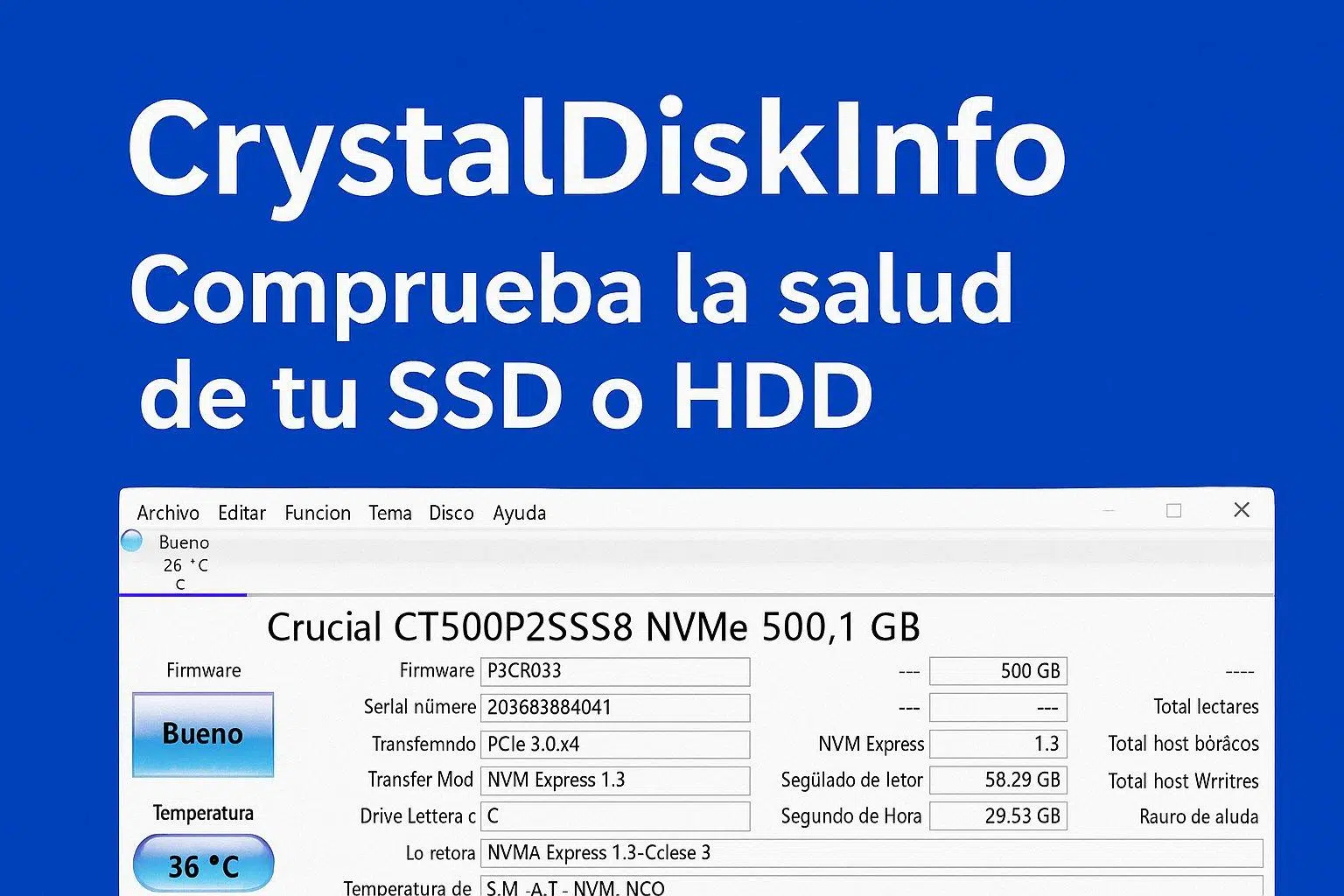
Al abrir CrystalDiskInfo te encuentras con una pantalla principal muy directa: arriba se selecciona la unidad (C:, D:, etc.) y en el resto de la ventana se agrupa la información más importante. Aunque parece mucho, se puede desglosar en bloques muy claros.
En la parte izquierda verás el “Estado de salud” y la temperatura. Según la versión, puede aparecer un cuadro de color (azul, amarillo, rojo) o un texto tipo “Good / Caution / Bad”. Esa valoración se basa en los parámetros SMART más críticos: sectores reasignados, errores graves, degradación extrema, etc.
Justo debajo figura la temperatura actual de la unidad, normalmente en grados Celsius. Lo habitual es moverse entre 30 °C y 45 °C en un uso normal. A partir de unos 50 °C conviene revisar la ventilación del equipo, y si ves más de 60 °C de forma sostenida en un SSD NVMe, plantéate añadir un disipador o mejorar el flujo de aire.
En el centro y zona derecha aparece la ficha técnica del disco o SSD, donde se incluye:
- Nombre del modelo: tal y como lo ha definido el fabricante en el firmware (a veces es el SKU y no el nombre comercial que ves en la caja).
- Capacidad detectada: el tamaño que ve el sistema operativo, que suele ser algo menor que la cifra de marketing (por el uso de gigabytes vs gibibytes y reservas internas).
- Firmware: versión del microcódigo interno. Útil para comprobar si hay actualizaciones del fabricante que corrijan errores o mejoren estabilidad.
- Número de serie: identificador único del dispositivo, muy práctico para gestionar garantías o detectar series problemáticas.
- Interfaz: indica cómo está conectado al equipo (SATA, NVM Express, USB, etc.).
- Modo de transferencia: muestra la velocidad máxima soportada y la que se está usando realmente (por ejemplo, SATA 6 Gb/s, PCIe 3.0 x4, PCIe 4.0 x4…).
- Letra de unidad: la letra asignada en Windows (C:, D:, E:…).
- Estándar: norma que sigue el dispositivo (ACS-2, NVM Express versión X, etc.).
- Características soportadas: lista de funciones como S.M.A.R.T., APM (gestión avanzada de energía), NCQ, TRIM, DevSleep y otras.
Un poco más a la derecha verás estadísticas de uso muy interesantes para evaluar su vida útil:
- Total Host Reads / Writes: cantidad total de datos leídos y escritos por el sistema, normalmente en gigabytes. Es clave para saber si te acercas al TBW garantizado por el fabricante en un SSD.
- Velocidad de rotación (solo HDD): revoluciones por minuto (RPM) de los platos mecánicos, 5400, 7200, etc.
- Nº de encendidos: cuántas veces se ha inicializado la unidad.
- Horas encendido: total de horas de funcionamiento acumuladas. Si pasas el ratón por encima, muchas versiones lo traducen también a días.
Con este bloque de datos ya puedes hacerte una primera idea clara: saber si el disco es muy viejo, si ha trabajado mucho, si su temperatura es razonable y si, en teoría, debería seguir en buen estado o conviene empezar a pensar en un reemplazo antes de que diga basta.
Cómo interpretar la tabla SMART: Current, Worst, Threshold y Raw
La parte más “misteriosa” de CrystalDiskInfo es la tabla inferior, donde aparecen decenas de atributos SMART con varias columnas de números. Aquí es donde de verdad se esconde el diagnóstico más fino de la salud del disco.
Antes de nada es muy recomendable cambiar la visualización de los valores en bruto. Ve al menú “Características” (o “Features”) → “Opciones avanzadas” → “Valores en bruto” y selecciona “10 ”. Así los “Raw Values” se mostrarán en decimal en lugar de hexadecimal, mucho más fácil de entender si no estás acostumbrado al formato base 16.
Un atributo típico, como “Read Error Rate” (Tasa de errores de lectura), tendrá columnas como estas: ID, Nombre, Current, Worst, Threshold, Raw Value. Lo importante es entender qué significa cada una, porque no todos los fabricantes usan la misma escala interna.
La columna “Current” (Actual) es el valor normalizado que representa el estado del atributo en este momento. Puede empezar en 100, en 200 o incluso en 253 según la marca. A medida que la situación empeora, este número suele bajar. Mientras “Current” se mantenga claramente por encima de “Threshold”, estamos en terreno razonablemente seguro.
La columna “Worst” (Peor) indica el peor valor que ha tenido ese atributo desde que el disco empezó a registrar datos SMART. Si “Worst” es igual a “Current”, significa que nunca ha estado peor que ahora. Si “Worst” es más bajo, hubo un momento en el pasado donde la situación era más crítica que en el presente (por ejemplo, una época con más errores de lectura que luego se estabilizaron).
La columna “Threshold” (Umbral) es la clave: es el límite por debajo del cual el fabricante considera que el atributo indica fallo inminente o condiciones peligrosas. Si “Current” sigue por encima de “Threshold”, el disco, según SMART, está todavía dentro de los márgenes aceptables. Cuando “Current” iguala o baja de “Threshold”, CrystalDiskInfo empezará a marcar el disco en amarillo (“Precaución”) o rojo (“Malo”).
La columna “Raw Value” (Valor bruto) almacena el dato real que utiliza la controladora para calcular ese valor normalizado. Aquí pueden ser desde contadores de errores (veces), sectores reasignados, ciclos de encendido, gigabytes escritos, hasta códigos poco claros. Lo ideal es tener la visualización en decimal para que, por ejemplo, un “10” signifique literalmente 10 errores o 10 eventos, en vez de un críptico “0A” hexadecimal.
Conviene insistir en que cada fabricante usa sus propias escalas y fórmulas. Ver un “Current: 200” en un SSD Samsung no significa que esté “mejor” que otro con “Current: 100” de otra marca; lo relevante es siempre la relación con el “Threshold” y el comportamiento a lo largo del tiempo, no el número aislado.
Atributos SMART más importantes que deberías vigilar
No hace falta volverse loco con todos los atributos SMART. Muchos son internos, dependen de cada fabricante y no tienen una traducción sencilla. Sin embargo, hay una serie de parámetros comunes que sí conviene tener muy controlados porque suelen ser la antesala de problemas serios.
Algunos de los más relevantes en la mayoría de unidades son:
- Reallocated Sectors Count (Sectores reasignados): indica cuántos sectores defectuosos se han movido a la zona de reserva del disco. Un pequeño número aislado no es dramático, pero si ves cómo el valor en bruto va subiendo con el tiempo, mal asunto.
- Current Pending Sector Count (Sectores pendientes): sectores inestables que todavía no se han reasignado. Si este contador crece, tienes muchas papeletas de empezar a ver archivos corruptos o errores de lectura.
- Uncorrectable Sector Count: sectores con errores que no se han podido corregir ni con mecanismos de recuperación de datos. Muy mala señal si se incrementa.
- Read Error Rate / Write Error Rate: tasas de errores de lectura/escritura. Depende mucho de la marca, pero si el “Raw Value” se dispara y además empiezas a notar cuelgues, algo no va bien.
- UltraDMA CRC Error Count: errores en la transmisión de datos entre el disco y la controladora (cable, conector, puerto SATA). Si el Raw Value empieza a subir, revisa cables y conexiones antes de culpar al disco.
- Power-On Hours (Horas de encendido): simple contador de horas. Un HDD con más de 20.000 horas ya está en edad de jubilación, aunque no marque errores.
- Power Cycle Count (Veces encendido): cuántas veces se ha energizado la unidad. También da pistas sobre el desgaste.
En los SSD hay atributos específicos de desgaste, como el porcentaje de vida restante, los bloques borrados o los terabytes escritos. Muchos fabricantes exponen directamente un atributo que se interpreta como “vida útil en porcentaje”, y CrystalDiskInfo lo traduce en un estado de salud fácil de entender.
Además, hay un atributo llamado “Unsafe Shutdowns” o similar en muchas unidades, que cuenta las veces que el dispositivo se ha quedado sin alimentación de forma brusca (apagón, cuelgue sin apagar correctamente, tirar del cable…). No tiene por qué significar un fallo inminente, pero un número alto indica un trato poco delicado al disco.
Códigos de colores y estados de salud en CrystalDiskInfo
CrystalDiskInfo utiliza un sistema muy visual para que no tengas que descifrar todo a mano. El indicador de salud y, en versiones antiguas, el gran recuadro de color, son tu semáforo rápido para decidir qué hacer.
Lo más habitual es encontrarse con estos estados:
- Azul / “Good” / “Bueno”: todos los atributos críticos están dentro de los umbrales establecidos. En principio no hay motivo para preocuparse, aunque en HDD muy viejos conviene seguir atento a sectores reasignados.
- Amarillo / “Caution” / “Precaución”: suele activarse cuando hay sectores reasignados, sectores pendientes o el porcentaje de vida restante de un SSD cae por debajo de cierto valor (por ejemplo, 10%). Es momento de hacer copia de seguridad y vigilar la evolución.
- Rojo / “Bad” / “Malo”: el disco ha superado claramente los límites que el fabricante considera seguros. Puede fallar en cualquier momento, así que lo razonable es copiar todo lo importante cuanto antes y planificar el reemplazo inmediato.
Estos colores y textos no afectan al funcionamiento del disco, solo son una interpretación del software basada en los datos SMART. Aun así, están muy bien ajustados en la mayoría de casos y son un buen indicio de si debes empezar a preocuparte o no.
También puedes personalizar algunas alertas desde el menú de funciones avanzadas: por ejemplo, fijar una temperatura máxima a partir de la cual te muestre una advertencia, o ajustar los umbrales para determinados contadores (como sectores reasignados o sectores pendientes), algo más orientado a usuarios avanzados.
Limitaciones de CrystalDiskInfo, sobre todo en discos mecánicos
Por muy útil que sea, hay que entender dónde están los límites de CrystalDiskInfo. El programa solo puede leer y mostrar lo que el firmware del disco registra en SMART. Todo lo que no llegue a ese registro interno, queda fuera de su alcance.
En discos duros mecánicos (HDD) esto es especialmente importante. Un HDD puede estar dando ya síntomas claros de desgaste: ruidos de cabezal, vibraciones, ralentizaciones al abrir carpetas, pequeños bloqueos al copiar archivos… y aun así seguir marcando “Good” porque todavía no se han reasignado sectores o los contadores de error no han cruzado los umbrales.
También hay casos en los que existen sectores lentos, pero no totalmente defectuosos, que provocan que Windows se quede pensando varios segundos al acceder a ciertos archivos, sin que el disco lo anote de inmediato como error SMART crítico. En ese escenario, CrystalDiskInfo puede seguir mostrando una salud aparentemente correcta mientras tú ya notas que algo no cuadra.
Por eso, con los HDD conviene combinar CrystalDiskInfo con otras herramientas como:
- CHKDSK (herramienta de Windows) para buscar y aislar sectores defectuosos a nivel de sistema de archivos.
- Escáneres de superficie tipo HDDScan, Victoria HDD o Hard Disk Sentinel, que revisan plato a plato y sector a sector.
- Tu propio oído y paciencia: si el disco hace ruidos extraños, chirridos o clics repetitivos, mala señal, aunque el SMART aún no esté gritando.
En los SSD la historia es distinta y bastante más favorable: no hay partes mecánicas, y el desgaste de las celdas de memoria se refleja mucho mejor en atributos SMART como bloques borrados, fallos de corrección ECC o porcentaje de vida restante. Aquí sí puedes tomar las advertencias de CrystalDiskInfo como una referencia muy sólida para decidir cuándo cambiar la unidad.
Opciones avanzadas y gráficos: exprimir CrystalDiskInfo a fondo
Más allá de mirar el estado de salud y cerrar el programa, CrystalDiskInfo tiene una buena batería de opciones avanzadas que permiten afinar su comportamiento y obtener una visión más completa de tus unidades.
En el menú “Función” (Function) puedes controlar, entre otras cosas:
- Frecuencia de actualización: cada cuánto tiempo refresca los datos SMART (por ejemplo, cada 1, 10 o 30 minutos). Útil si lo dejas abierto de fondo.
- Qué unidades se actualizan: puedes indicar si quieres que monitorice todas las unidades, solo algunas o ninguna (útil para ahorrar recursos o evitar confusiones).
- Reescanear dispositivos: la opción “Volver a detectar” fuerza al programa a buscar de nuevo discos conectados, muy interesante si estás cambiando unidades en caliente, especialmente en NAS o equipos con bahías hot-swap.
- Mostrar gráficos: permite representar en gráficas la evolución de parámetros como la temperatura, el estado de salud o algunos atributos SMART concretos. Es bastante cómodo para ver tendencias en el tiempo.
Dentro de “Opciones avanzadas” hay bastantes configuraciones potentes que conviene tocar solo si sabes lo que haces:
- Control AAM/APM: ajusta el nivel de gestión avanzada de energía y ruido de algunos discos. En la práctica casi nadie necesita cambiarlo; mejor dejarlo como viene de fábrica.
- Detección avanzada de disco, Intel RAID, AMD RAID, USB/IEEE1394, ATA Pass Through: controlan cómo busca y detecta unidades en distintos tipos de controladora y modos RAID. Solo es recomendable modificarlos si el programa no ve algún disco que debería detectar.
- Escala de temperatura: elegir entre °C y °F.
- Modo de residencia: decidir si quieres que el programa se minimice a la bandeja del sistema y se inicie con Windows, algo muy cómodo si quieres una supervisión continua.
- Ocultar discos sin SMART: si tienes unidades que no exponen datos SMART, puedes ocultarlas para no llenar la lista de discos “vacíos”.
También puedes configurar avisos y alarmas para que CrystalDiskInfo te avise, por ejemplo, si la temperatura supera cierto umbral o si el estado de salud baja por debajo de un porcentaje concreto. No es que sustituya a un sistema de monitorización profesional, pero para un PC doméstico va sobrado.
SMART: la tecnología clave que hay detrás de CrystalDiskInfo
Todo lo que ves en CrystalDiskInfo existe gracias a la tecnología SMART. Esta capa de monitorización se empezó a gestar en los años 90 para intentar anticipar fallos en discos duros mecánicos y ha ido evolucionando con el tiempo hasta abarcar también SSD SATA y NVMe.
La idea de SMART es que el propio disco sea capaz de vigilarse internamente, analizando parámetros como temperatura, errores, reintentos de lectura, vibraciones, ciclos de escritura… y, en teoría, lanzar una especie de “aviso preventivo” antes de que se produzca un fallo catastrófico. En la práctica no es perfecto, pero ha evitado muchas pérdidas de datos.
CrystalDiskInfo funciona como una especie de intérprete de esos datos SMART, que normalmente están en forma de valores hexadecimales y tablas que el usuario medio no sabría ni por dónde coger. El programa decodifica esa información, la mapea a atributos con nombres comprensibles y aplica reglas de color para representar el estado general.
Cuando un contador de sectores defectuosos, por ejemplo, supera el umbral marcado por el fabricante, el firmware del disco ya considera que el dispositivo está en mala situación, y CrystalDiskInfo lo traduce en un estado “Caution” o “Bad”. Este sistema de vigilancia en tiempo real permite que, con abrir el programa un momento, sepas si estás jugando con fuego o todavía te queda cuerda.
Aun así, SMART no es infalible ni está exento de limitaciones. Por ejemplo, no siempre puede anticipar fallos eléctricos repentinos, subidas de tensión, golpes físicos o problemas de la placa base. Tampoco todos los fabricantes exponen los mismos atributos ni los interpretan igual. Por eso hay que tomarlo como una ayuda muy valiosa, pero no como una garantía absoluta de que nunca se producirá un fallo inesperado.
Qué hacer si CrystalDiskInfo marca errores o tienes síntomas raros
Si abres CrystalDiskInfo y ves que el disco aparece en amarillo o rojo, o si aunque marque “Bueno” notas cuelgues, ruidos extraños o lentitud extrema, no lo dejes pasar. Cuanto antes actúes, más posibilidades tendrás de salvar tus datos.
Las medidas mínimas que deberías tomar son estas:
- Copia de seguridad inmediata: lo primero es guardar tus documentos, fotos y proyectos importantes en otra unidad, un NAS o la nube. No esperes a “ver si aguanta un poco más”.
- No sobrescribir más de la cuenta: evita instalar programas nuevos o llenar el disco problemático. Reducir la actividad disminuye el riesgo de que empeore de golpe.
- Revisar el sistema de archivos con herramientas de Windows: comandos como sfc /scannow o DISM /Online /Cleanup-Image /RestoreHealth pueden arreglar archivos del sistema dañados que a veces se confunden con fallos de disco.
- Ejecutar CHKDSK en HDD: para discos mecánicos, usar chkdsk X: /f /r (cambiando X: por la letra de la unidad) permitirá buscar y aislar sectores defectuosos. Eso sí, el proceso puede tardar muchas horas en discos grandes.
- En SSD mejor usar herramientas del fabricante: comandos de escaneo agresivos como /r en CHKDSK fuerzan lecturas masivas y pueden añadir desgaste innecesario. Es preferible recurrir a utilidades como Samsung Magician, Crucial Storage Executive, WD Dashboard, Kingston SSD Manager, ADATA SSD Toolbox, etc.
Si después de estos pasos el sistema sigue dando guerra, o los atributos críticos continúan empeorando en SMART (sobre todo sectores reasignados, pendientes o errores no corregibles), lo más sensato es dar por amortizada la unidad y sustituirla. Los discos duros y SSD tienen fecha de caducidad, aunque no venga impresa en grande en el frontal.
Herramientas como Hard Disk Sentinel o HDDScan pueden darte un análisis más profundo, con tests de superficie y pronósticos más elaborados. Yo suelo usar CrystalDiskInfo para el chequeo rápido y, si huele a chamusquina, paso a algo más avanzado antes de decidir si tiro de garantía o reemplazo directamente.
Como idea general, CrystalDiskInfo es una especie de cuadro de mando para tus discos: sencillo, visual y lleno de datos útiles si sabes leerlos. Usado con cabeza, combinado con buenas copias de seguridad y algún escaneo extra cuando haga falta, te permite adelantarte a muchos problemas que, de otra forma, acabarían en pérdidas de datos y disgustos mayúsculos.
